When you are no longer able to resize the Tag Editor window to work with Trados Workbench do this:
1. Go to Start > Run
2. Type "regedit"
3. Go to keyname HKEY_CURRENT_USER\Software\Trados\TagEditor\Settings
4. Right click on this key and choose Export. Please choose a location
to temporarily save a backup of this entry. Your Desktop is fine.
5. Delete the "Top", "Bottom", "Left" and "Right" entries from the right hand window.
6. Close the Registry Editor.
Please reopen TagEditor and you should now be able to maximise and
minimise the TagEditor window. If this has worked successfully then feel
free to delete the registry key backup which you made earlier.
Wednesday, December 29, 2010
Friday, December 24, 2010
How to Pronounce "the" in English
Normally, we pronounce "the" with a short sound (like "thuh"). But when "the" comes before a vowel sound, we pronounce it as a long "thee".
| vowel sound | we write | we say |
| A | the apple | thee apple |
| E | the egg | thee egg |
| I | the ice-cream | thee ice-cream |
| O | the orange | thee orange |
| U | the ugli fruit | thee ugli fruit |
| we write | with | we say | with |
| the house | consonant (h) | thuh house | consonant sound |
| the hour | consonant (h) | thee our | vowel sound |
| the university | vowel (u) | thuh youniversity | consonant sound |
| the umbrella | vowel (u) | thee umbrella | vowel sound |
When we wish to place emphasis on a particular word, we can use "emphatic the" [thee], whether or not the word begins with a consonant or vowel sound. For example:
A: I saw the [thuh] President yesterday.
B: What! The [thee] President of the United States?
A: Yes, exactly.
When to Say "a" or "an"
The indefinite article is a or an. But how do we know when to say a and when to say an?
The rule is really very simple. It depends on the sound at the start of the following word. (It does not depend on the way we write the following word, it depends on the way we say it.)
A + consonant sound
If the following word starts with a consonant sound, then we say a.| a cat |
| a game of golf |
| a human emotion |
| a Peruvian |
| a very fat woman |
AN + vowel sound
If the following word starts with a vowel sound, then we say an.| an apple |
| an extremely easy job |
| an interesting film |
| an old man |
| an umbrella |
The importance of sound
Normally, we pronounce consonant letters with a consonant sound, and vowel letters with a vowel sound. But there are some exceptions. The rule about a or an is still the same. You just need to think about the sound, not the writing. Look at these examples:| consonant letter with vowel sound | |
| an honest man | on-est |
| an hour | our |
| an FBI agent | eff-bee-eye |
| vowel letter with consonant sound | |
| a European country | you-ro-pe-an |
| a one-day conference | won-day |
| a university | you-ni-ver-si-ty |
- When the definite article (“the”) comes before a word that begins with a vowel, pronounce it like “thee.” E.g. “<thee> elephant”
- When “the” comes before a word that begins with a consonant, pronounce it like “thu” (with a schwa sound). E.g. “<thu> car”
One writer on a linguistics mailing list claims that some people pronounce “the” as “thu,” regardless of the word that follows. However, this pronunciation isn’t standard (when followed by a word beginning with a vowel). It might be attributable to a regional or class dialect, but I don’t know for sure.
You may find additional information at one of these places:
- The British Council:
The United Kingdom’s international organisation for educational and cultural relations
- International EFL Cafe
Saturday, November 20, 2010
How to Crack Password-protected Zip Files Using Linux
How to Crack Password-protected
Zip Files Using Linux: In case you or your friend has forgotten the
password of your password-protected .zip file that may contain important
documents, music, or non-porn movies, there is really no need to worry
as there are plenty of password crackers available out there. If you are
using Linux, I highly recommend you download and use FCrackZip.
FCrackZip
is a simple, fast, free, and easy-to-use zip cracker that is similar to
fzc and zipcrack. Partially written in assembler, it uses brute force
or dictionary based attacks to find the password. Although you will need
the Linux terminal to use FCrackZip, a simple command is actually required to crack the zip password.
If
you are using any popular or major Linux distribution, FCrackZip should
be available on the software repository, and you could download it
using the package manager. You may also download the latest version from
HERE.
Since I'm using Ubuntu, I quickly installed FCrackZip from the command line using this command:
$ sudo apt-get install fcrackzip
After installing FCrackZip, you can either use brute force or dictionary mode to crack the password.
Here is a sample FCrackZip command one-liner using brute force:
$ fcrackzip -v -b -p aaaaaa -u your_zip_file.zip

From
the screenshot above, you will see that I've successfully cracked a
password protected zip file using the brute force method. From my
experience, it took around 30 minutes to find password, but it is worth
the wait. Source: http://www.junauza.com
Monday, November 15, 2010
Secure Mysql Database!
You can use robots.txt or the .htaccess file, so that google doesn’t index the mySQL inc files.
Type in Google the following sentence filetype:inc intext:mysql_connect
The result is a big list of web sites with the inc files indexed in google, with the username and password of the users of the databases, for example the root user. Beware!
Sunday, November 7, 2010
Translating WordFast TXML in memoQ
WordFast as a Word add-on (currently version Classic) was always
quite popular – it was not expensive, simple and fully compatible with
Trados. However, last year the company released a completely new version
– WordFast Pro is written from the ground up in Java, which makes it
possible to use it on different operating systems (Windows, Linux,
MacOS). The software works in table layout typical for all new CAT tools
and is… quite specific. It does have a lot of fans, unfortunately I
don’t like it (especially the terrible way it handles insertion of
tags). Luckily, we don’t have to translate .txml files using WordFast,
it can be done with memoQ. Below you’ll find the procedure step-by-step.
Recently I’m getting a lot of translations in WordFast Pro files. The first translation I did using WF demo and I didn’t liked it, so when I got the next ones, I looked for a way to process them in a much more comfortable environment, that is memoQ. As it came out, it isn’t so hard.
What do we need:
 The procedure may seem complicated, especially at first, but after
the software configuration, the preparation and file opening wont’ take
much more time than in case of any other file format. The situations
becomes a bit more complicated when along with TXML files client sends
us a WordFast TM file with the .txt extension. To use this TM in memoQ
we have to prepare it by removing unnecessary data and tags.
The procedure may seem complicated, especially at first, but after
the software configuration, the preparation and file opening wont’ take
much more time than in case of any other file format. The situations
becomes a bit more complicated when along with TXML files client sends
us a WordFast TM file with the .txt extension. To use this TM in memoQ
we have to prepare it by removing unnecessary data and tags.
Recently I’m getting a lot of translations in WordFast Pro files. The first translation I did using WF demo and I didn’t liked it, so when I got the next ones, I looked for a way to process them in a much more comfortable environment, that is memoQ. As it came out, it isn’t so hard.
What do we need:
- WordFast Pro demo (not necessary, but recommended)
- Excel/Calc
- memoQ
- Word/Writer (optional)
- Open the file to translate (.txml) in the WordFast.
- Use Ctrl-Alt-Ins to copy all source segments contents into target segments.
- Save the file, close WordFast (repeat the procedure for additional files if necessary). If, for some reason, you don’t want or can’t use the WordFast demo, you can use the search/replace procedure described here.
- Download this filter file and save it on your disc.
- Start the memoQ.
- From the Tools menu choose Resource console, then Filter configurations and Import new from the left pane. Select the file saved in step 4.
- Create new project, in the Add document window select Add document as. You’ll have to switch file type filter in the lower part of the window from All supported files to All files (*.*). Select the txml file(s) saved in step 3.
- In the Document import settings click the yellow folder icon (Load filter configuration) and select WordFast
filter imported in step 6. The filter works by hiding the original
source segments (<source>), displaying for edition target segments
(<target>) and defining handling of WordFast tags. See picture
below.
Tip: WordFast tags, displayed natively as consecutive numbers {1}, {2}, {3}, in memoQ are displayed as “inline” tags. By default you can insert them using F9 key, but in my there are more convenient key combinations, for example Ctrl-Alt-Down, like in Trados. To modify keyboard settings choose Tools > Resource console > Keyboard shortcuts > Clone (for the Default) > Edit.TXML file imported to memoQ. Source segments (<source>) you can see in the preview pane below are hidden, you can translate only <target> segments.
- After translation export the finished file using Export command. Excellent QA features of memoQ won’t allow you to export files with tags mismatch and will show you the affected segments (if any).
- Just to be extra sure you can open the translated file in WordFast, to check if everything is OK.

WordFast Pro window. Use Ctrl-Alt-Ins to copy all source language segments to target segments.

Finished translation in WordFast. The percentage of TM substitutions are shown.
- Open the TM file in Word (or OpenOffice Writer) (option). In the WF TM tags are encoded as &tA;, &tB;, &tC;, etc. It is possible to remove them all at once using Word. Open Search & Replace window (Ctrl-H), click More >> button and select Use wildcards. Enter \&t[A-Z]\; in the Find field. Leave the Replace field empty. Click Replace all button. Now deselect Use wildcards checkbox and replace &’A9; with ©, and &’AE; with ® (of course, if there are such strings in your TM. Save as text file using UTF-8 encoding.
- Start Excel (or OpenOffice Calc), import the TM file by selecting Data > External data > From text. Choose Tab as a column separator and import the first row checkbox.
Where to find a text import command.
- Remove all columns except the ones with source and target texts. In
the example above we have to remove columns A, B, C, D, F, H and I,
leaving only E and G. As an alternative we can leave also column B, with
the translators ID.
WordFast TM file correctly imported into Excel.
- Enter the language identifiers into first row of source and target
columns. If necessary, we can add columns with additional information,
like the translation author, domain, client, etc.
File with unnecessary data removed and additional column added (in this case - translation agency name).
- If step 1 was skipped, you have to remove tags – unfortunately, Excel requires removing them one by one, i.e. you have to enter manually all possible letter combinations (see step 1). Save the file: select round office button > Save as > Other formats > Unicode text. Close Excel.
- In memoQ select an existing memory or create a new one. Choose the Import from TMX/CSV command. Select the file saved in step 5.
- In the Translation memory CSV import settings window select proper settings:
- File encoding – UTF-8
- Delimiter – Tab
- First row is header
- Voila.




Saturday, October 30, 2010
Restore the Windows Boot Loader After an Ubuntu Update
Will your computer not boot into Windows after installing an update
on your dual-boot or Wubi Ubuntu install? Here’s how you can get your
Windows boot loader back so you can easily get back to work in either
OS.
We’ve mentioned before how Wubi is a great way to run Ubuntu on your Windows PC or netbook, and in general it works great. However, sometimes your system may receive updates to GRUB, and if you choose the wrong option, the next time you reboot your computer you may find that it think there’s only Ubuntu and no Windows installed on your computer.

Or, perhaps, even more ominously, you boot your computer to see that it thinks it has no operating system.

Often, there’s no need to panic. If you recently received an Ubuntu update, or somehow managed to mess up or remove your boot loader, it’s quick and easy to get it back using familiar Windows tools. Here’s how.

Save the changes and reboot your computer from the Windows DVD. After a few moments, you should see the install setup screen. Select your preferred language, then click Next.

Your install disk is designed to install Windows on your computer, but also contains tools to help repair your existing Windows install. On the bottom left of the Install window, click the Repair your computer link to get started repairing your current install of Windows.

System Recovery will automatically start scanning to see if there’s an existing Windows install with something it can easily fix automatically. You may have to wait a few minutes while it scans your computer.

If your only problem is the boot loader, often it will automatically detect the problem and offer to fix it. If so, simply click Repair and restart, and your computer should be booted back into Windows as normal within minutes.


Now, select Command Prompt from the available recovery tools.

In the command prompt window, enter the following to repair your boot loader:

Moments later, you should see your standard Windows login screen as normal, and all of your files and programs should be fine and ready to use.

As you may notice, the option to boot into Ubuntu will no longer show up in your boot menu, and your computer will act like you only have Windows installed. To get your Wubi Ubuntu or full Ubuntu install accessable from the boot loader again, you’ll need to restore it as well. The easiest way is to Add Wubi Back to the Bootloader With EasyBCD. Once you’ve done that, you should be back in business, ready to use Windows or Ubuntu as you need. Source: http://www.howtogeek.com
We’ve mentioned before how Wubi is a great way to run Ubuntu on your Windows PC or netbook, and in general it works great. However, sometimes your system may receive updates to GRUB, and if you choose the wrong option, the next time you reboot your computer you may find that it think there’s only Ubuntu and no Windows installed on your computer.
Or, perhaps, even more ominously, you boot your computer to see that it thinks it has no operating system.
Often, there’s no need to panic. If you recently received an Ubuntu update, or somehow managed to mess up or remove your boot loader, it’s quick and easy to get it back using familiar Windows tools. Here’s how.
Reinstall Your Windows Boot Loader From the Windows DVD
To get back into Windows, you’ll need to reinstall your Windows boot loader. Thankfully this isn’t as difficult or time consuming as reinstalling Windows, but it will require your Windows DVD. Boot your computer from the DVD, and if it doesn’t automatically offer to let you boot from the disk, you may need to change your boot settings in the BIOS. You can usually access by pressing the F2, F10, or Delete key on the initial boot screen, depending on your computer.Save the changes and reboot your computer from the Windows DVD. After a few moments, you should see the install setup screen. Select your preferred language, then click Next.
Your install disk is designed to install Windows on your computer, but also contains tools to help repair your existing Windows install. On the bottom left of the Install window, click the Repair your computer link to get started repairing your current install of Windows.
System Recovery will automatically start scanning to see if there’s an existing Windows install with something it can easily fix automatically. You may have to wait a few minutes while it scans your computer.
If your only problem is the boot loader, often it will automatically detect the problem and offer to fix it. If so, simply click Repair and restart, and your computer should be booted back into Windows as normal within minutes.
Reinstall Your Boot Loader Manually From the Windows DVD
Alternately, if it doesn’t automatically detect anything to fix, you’ll have to choose your own recovery options. Click the bullet option on the top then click Next to use recovery tools to fix Windows.Now, select Command Prompt from the available recovery tools.
In the command prompt window, enter the following to repair your boot loader:
bootrec /rebuildbcdAfter a few moments, it should detect your Windows installation and ask if you want to add it to the boot loader. Enter Y to add it, then exit the command prompt and reboot your computer when you’re finished.
Moments later, you should see your standard Windows login screen as normal, and all of your files and programs should be fine and ready to use.
As you may notice, the option to boot into Ubuntu will no longer show up in your boot menu, and your computer will act like you only have Windows installed. To get your Wubi Ubuntu or full Ubuntu install accessable from the boot loader again, you’ll need to restore it as well. The easiest way is to Add Wubi Back to the Bootloader With EasyBCD. Once you’ve done that, you should be back in business, ready to use Windows or Ubuntu as you need. Source: http://www.howtogeek.com
Tuesday, October 26, 2010
Download Rapidshare and Megaupload files from the Linux Terminal
To download any Rapidshare and
Megaupload file from the Linux terminal, you will need to install an
application called 'plowshare'. You can get it from HERE.
Before using plowshare, you should install these packages first:
curl
recode
imagemagick
tesseract-ocr
rhino
aview
PerlMagick
Since I'm using Ubuntu, I downloaded and installed those packages using this one-liner:
$ sudo apt-get install curl recode imagemagick tesseract-ocr-eng rhino aview perlmagick
Now
that everything is set, you could start downloading Rapidshare and
Megaupload files using the Linux terminal. Here are some usage examples:
Downloading a file from Rapidshare:
$ plowdown http://www.rapidshare.com/files/12345678/Elephants_Dream.rar
Downloading a file from Megaupload (with free membership account):
$ plowdown -a myusername:mypassword http://www.megaupload.com/?d=12345678
Downloading a password-protected file from Megaupload:
$ plowdown -p somepassword http://www.megaupload.com/?d=swf1g53x
For other usage examples, you may go HERE.
It
is worth noting that plowshare also supports other file-sharing
services such as 2Shared, 4Shared, ZShare, Badongo, Divshare.com,
Depositfiles, Mediafire, Netload.in, Storage.to, Uploaded.to,
Uploading.com, Sendspace, and Usershare. Source: http://www.junauza.com
Usage examples
All four scripts share the same verbose options: -v0 (alias: -q), -v1 (errors only), -v2 (infos message; default), -v3 (show all messages).
Download
- Download a file from Rapidshare:
$ plowdown http://www.rapidshare.com/files/86545320/Tux-Trainer_25-01-2008.rar
- Download a list of links (one link per line):
$ plowdown file_with_links.txt
- Download a list of links (one link per line) commenting out (with #) those successfully downloaded:
$ plowdown -m file_with_links.txt
- Limit the download rate (you can use curl rates: K=Kbps, M=Mbps, G=Gbps):
$ plowdown -r 50K http://www.rapidshare.com/files/86545320/Tux-Trainer_25-01-2008.rar
- Download a file from Megaupload using a free membership account (note ':' is used to separate user from password):
$ plowdown -a myuser:mypassword http://www.megaupload.com/?d=132348234
- Download a password-protected file from Megaupload:
$ plowdown -p somepassword http://www.megaupload.com/?d=ieo1g52v
- Use a different web retriever for the last file download. File URL, file name and cookies are available through interpolations. Let's say you want to use wget:
$ plowdown --run-download='wget -O "%filename" --load-cookies "%cookies" "%url"' http://www.2shared.com/file/4446939/c9fd70d6/Test.html
- Filter alive links in a text file
$ plowdown -c file_with_links.txt > file_with_active_links.txt
Upload
- Upload a file to the Rapidshare collector zone
$ plowup --auth-freezone=myuser:mypassword /path/myfile.txt rapidshare
- Upload a file to Rapidshare anonymously changing uploaded file name:
$ plowup /path/myfile.txt rapidshare:anothername.txt
- Upload a file to Megaupload with a free membership account:
$ plowup -a myuser:mypassword -d "My description" /path/myfile.txt megaupload
- Upload a file to Megaupload with a premium account and multifetch upload:
$ plowup -a myuser:mypassword -d "My description" --multifetch http://www.somewherefarbeyond.com/somefile megaupload
- Upload a bunch of files (anonymously to 2shared):
$ plowup /path/myphotos/* 2shared
Notice that only files will be sent, subdirectories will be ignored.
Be aware that curl is not capable of uploading files containing a comma (,) in their name, so make sure to rename them before using plowup.
Delete
- Delete a file from megaupload (a premium account may be required):
$ plowdel -a myuser:mypassword http://www.megaupload.com/?d=132348234
List
- List links contained in a shared-folder link and download them all safely:
$ plowlist http://www.mediafire.com/?sharekey=79ac821ea0110 > links.txt $ plowdown -m links.txt
Linux dictionary tools
The dictionary is a tool that any writer or student should have on their computer. And Linux users are not immune from this need. But if you look through the possibilities of Linux dictionary tools you find quite a large amount available. Which of these tools are the best or easiest to use?
I have found, outside of using an application’s built-in spell checking, two particular tools that I prefer. These tools are GoldenDict and Dict. The former is a splendid GUI tool, whereas the latter is a lightning-quick command line tool. Let’s see which of these tools suits your needs best.
GoldenDict
GoldenDict is a feature-rich graphical dictionary program that allows the user to take advantage of multiple local dictionaries as well various on-line dictionaries. It’s easy to use and actually works in conjunction with other applications.
To install GoldenDict just do the following:
- Open up your Add/Remove Software Utility.
- Search for “goldendict” (No quotes).
- Mark GoldenDict for installation.
- Click Apply to install.
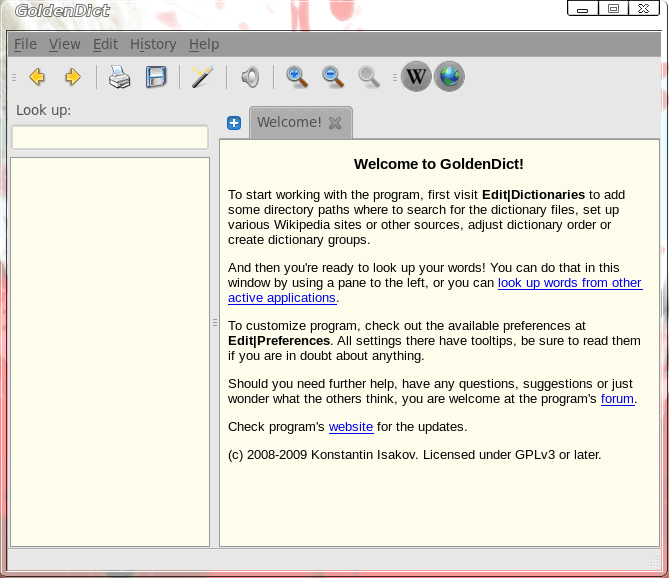
Figure 1
When you fire up GoldenDict you will the main window where you can take care of all of your lookups (see Figure 1). The usage is fairly straight-forward. You enter your word in the “Look up” text area and hit Enter. The results will appear as the disambiguation in the left pane and the actual definition in the right pane.
Now…let’s say you want to extend GoldenDict out to your other applications. If you click on Edit > Preferences and then click on the Scan Popup tab you can enable GoldenDict to work on any text you highlight in any application. I will warn you…this can get in the way of every day use. To that end I always enable this feature but enable it along with the “Only show popup when all selected keys are kept pressed”. With this feature you can configure a key (either Alt, Ctrl, Shift, or Meta) that must be pressed along with the word selection. When this combination is done a popup will appear definining the word.
Dict
Now let’s take a look at a much simpler tool – dict. Dict is a command line only tool that allows you to search online dictionaries (or local dictionaries if you have them installed) for word definitions. Installing dict is simple:
- Open up a terminal window.
- Issue the command sudo apt-get install dict (or a suitable command for your distribution).
- Accept the dependencies.
- Wait until the installation is complete.
dict -h SERVER WORD
Where SERVER is the server you want to use and WORD is the word you want to look up. Normally you could just issue dict WORD but currently the default servers for dict are all not responding. So in order to get around that you need to define a server to use. One server that is working is dict.tu-chemnitz.de. To use this server you would issue the command:
dict -h dict.tu-chemnitz.de WORDWhere WORD is the word you want to look up. You would then be rewarded with the definition of the word in question. Source: ghacks.net
Lingoes, Multi-Language Dictionary And Text Translation Software
Lingoes is a free dictionary and text translation software for the
Windows operating system. The application offers an incredible feature
set for a free program, more about that later in the review.
The program ships with an English dictionary and integration of multiple online translation services. Free dictionary files for additional languages are offered at the developer website. They need to be downloaded, unpacked and then loaded into the application.

All dictionaries are accessible at the same time. Words or phrases can be looked up by entering them in the search form on top of the program. Lingoes will automatically display the best match, and adjacent words in its interface.
The word definitions and phonetic form are displayed on the results page, along with the dictionary it has been found in. Phrases can also be picked with the mouse directly in the sidebar. Lingoes tries to automatically match the phrase to one of the installed dictionaries. It is possible to select a specific dictionary instead if the user wants to look up a phrase in one of the available dictionaries. Otherwise, the first matching dictionary will be used for the definition.
Dictionaries are added in the dictionary options menu. Here it is possible to install or uninstall dictionaries

A right-click on a word or phrase opens a context menu with several options, including possibilities to let the program pronounce the selected text, and search or print it.
A click on text translation in the main menu opens a small text input form in the program. Text entered into the form can be translated using one out of 13 different translation services ranging from Google Translate to Baidu Translation and Yahoo Babelfish.
The translated text is directly displayed in the program interface.

Text translation and dictionary look ups are the two main features of Lingoes. Hotkeys are available to use the program’s functionality on a system wide level.

This feature worked nicely in all tested programs, from Firefox over Thunderbird to Microsoft Office. The program hotkeys are defined in the program configuration. Here are the most important standard hotkeys:
Lingoes is an excellent program for users who need dictionary and / or text translation functionality on a regular basis. The program is available as a portable version or installer, and can be extended to work with more than 80 different languages. Source: http://www.ghacks.net
The program ships with an English dictionary and integration of multiple online translation services. Free dictionary files for additional languages are offered at the developer website. They need to be downloaded, unpacked and then loaded into the application.
All dictionaries are accessible at the same time. Words or phrases can be looked up by entering them in the search form on top of the program. Lingoes will automatically display the best match, and adjacent words in its interface.
The word definitions and phonetic form are displayed on the results page, along with the dictionary it has been found in. Phrases can also be picked with the mouse directly in the sidebar. Lingoes tries to automatically match the phrase to one of the installed dictionaries. It is possible to select a specific dictionary instead if the user wants to look up a phrase in one of the available dictionaries. Otherwise, the first matching dictionary will be used for the definition.
Dictionaries are added in the dictionary options menu. Here it is possible to install or uninstall dictionaries
A right-click on a word or phrase opens a context menu with several options, including possibilities to let the program pronounce the selected text, and search or print it.
A click on text translation in the main menu opens a small text input form in the program. Text entered into the form can be translated using one out of 13 different translation services ranging from Google Translate to Baidu Translation and Yahoo Babelfish.
The translated text is directly displayed in the program interface.
Text translation and dictionary look ups are the two main features of Lingoes. Hotkeys are available to use the program’s functionality on a system wide level.
This feature worked nicely in all tested programs, from Firefox over Thunderbird to Microsoft Office. The program hotkeys are defined in the program configuration. Here are the most important standard hotkeys:
- Alt-P: Pronounce
- Ctrl-F12: Speak selected text
- Ctrl-Alt-F12: Stop speaking
- Alt-G: Enable / Disable capture word on screen
- Alt-Z: Enable / Disable translate selected text
Lingoes is an excellent program for users who need dictionary and / or text translation functionality on a regular basis. The program is available as a portable version or installer, and can be extended to work with more than 80 different languages. Source: http://www.ghacks.net
Sunday, October 3, 2010
How To Remove Plugins From Firefox
One of the most annoying things in Firefox is that third party
software can install add-ons and plugins without the user’s consent.
That’s a big no-no from a security standpoint obviously, and it remains a
mystery why the developers have never bothered to fix that flaw by
adding a confirmation dialog whenever a new plugin or add-on tries to
install itself automatically.
We leave it at that for the moment. Now, Firefox users end up with plugins installed that they have not added to the browser. On our test system those were for instance: (name, description)

Plugins can be disabled in the Plugins manager, but not uninstalled or removed completely from the web browser. Entering about:plugins in the Firefox address bar will display additional information about each installed plugin. Users who visit the screen for the first time may want to type in about:config first, to change the preference plugin.expose_full_path to true. This displays the path to the plugin in the about:plugins dialog.
Displaying the path to the plugin does one thing: It enables the user to locate the plugin source on the hard drive. Just open the folder on the hard drive afterwards, backup the plugin file and delete it afterwards to remove it completely from Firefox. Here is how it is done for the two Microsoft Office 2010 plugins.

Locate the plugin paths in about:plugins and open the folders on the hard drive. In the case of Microsoft Office 2010, both plugins are located in the C:\Program Files (x86)\Microsoft Office\Office14\ folder on the hard drive (Please note, that the location on 32-bit systems is C:\Program Files\Microsoft Office\Office14\ instead).
The name of the first plugin is NPAUTHZ.DLL, the one of the second NPSPWRAP.DLL. We highly suggest to backup plugins before deleting them from the system, just in case they need to be restored at a later time. Plugins can be deleted while the browser is running, and doing so will immediately remove most of them from the about:plugins information window and the plugins manager in Tools > Add-ons. Some plugins may require a browser restart before they are completely removed from the browser.
To remove all plugins that are not used or needed simply go through the listing of plugins in about:plugins, locate the paths of those plugins on the hard drive, and backup and delete the plugin files.
There is also the possibility that some plugins have added themselves in the Windows Registry, Google Update comes to mind for instance. You can take a look at this guide How To Stop Automatic Plugin Installations In Firefox for an in depth walkthrough, or locate HKLM\Software\MozillaPlugins or HKLU\Software\MozillaPlugins in the Windows Registry to see if plugins have been added there as well. Again, export the Registry key first before deleting it, for the ability to restore the setting at a later time.
Source: http://www.ghacks.net
We leave it at that for the moment. Now, Firefox users end up with plugins installed that they have not added to the browser. On our test system those were for instance: (name, description)
- Google Update: Google Update
- Microsoft Office 2010: Office Authorization plug-in for NPAPI browsers
- Microsoft Office 2010: The plug-in allows you to open and edit files using Microsoft Office applications
- Quicktime Plug-In: The Quicktime Plugin allows you to view a wide variety of multimedia content in Web pages. For more information, visit the QuickTime Web site.
- Silverlight Plug-In
- Windows Live Photo Gallery: NPWLPG
Plugins can be disabled in the Plugins manager, but not uninstalled or removed completely from the web browser. Entering about:plugins in the Firefox address bar will display additional information about each installed plugin. Users who visit the screen for the first time may want to type in about:config first, to change the preference plugin.expose_full_path to true. This displays the path to the plugin in the about:plugins dialog.
Displaying the path to the plugin does one thing: It enables the user to locate the plugin source on the hard drive. Just open the folder on the hard drive afterwards, backup the plugin file and delete it afterwards to remove it completely from Firefox. Here is how it is done for the two Microsoft Office 2010 plugins.
Locate the plugin paths in about:plugins and open the folders on the hard drive. In the case of Microsoft Office 2010, both plugins are located in the C:\Program Files (x86)\Microsoft Office\Office14\ folder on the hard drive (Please note, that the location on 32-bit systems is C:\Program Files\Microsoft Office\Office14\ instead).
The name of the first plugin is NPAUTHZ.DLL, the one of the second NPSPWRAP.DLL. We highly suggest to backup plugins before deleting them from the system, just in case they need to be restored at a later time. Plugins can be deleted while the browser is running, and doing so will immediately remove most of them from the about:plugins information window and the plugins manager in Tools > Add-ons. Some plugins may require a browser restart before they are completely removed from the browser.
To remove all plugins that are not used or needed simply go through the listing of plugins in about:plugins, locate the paths of those plugins on the hard drive, and backup and delete the plugin files.
There is also the possibility that some plugins have added themselves in the Windows Registry, Google Update comes to mind for instance. You can take a look at this guide How To Stop Automatic Plugin Installations In Firefox for an in depth walkthrough, or locate HKLM\Software\MozillaPlugins or HKLU\Software\MozillaPlugins in the Windows Registry to see if plugins have been added there as well. Again, export the Registry key first before deleting it, for the ability to restore the setting at a later time.
Source: http://www.ghacks.net
Friday, October 1, 2010
Autokey: Make Your Own Keyboard Shortcuts In Linux
Few days ago, we discussed the usefulness of Spark and how it enables you to create custom shortcut keys in Mac. Alternatively, in Windows, we can use the popular AutoHotKey to create custom shortcuts. So what about Linux? Autokey is probably the best answer.
AutoKey is a desktop automation utility for Linux and X11. It allows you to create scripts and assign hotkeys to these scripts, allowing you to execute them on demand in whatever program you are using.
Open a terminal and type:
For Gnome user:
For KDE users:

You will see on the left pane two folders named My Phrases and Sample Scripts. The My Phrases folder is binded to the hotkey “Ctrl + F7“.
To get a feel of the capability of Autokey, open a text editor and press Ctrl + F7, you should see the context menu with Address option. When you select the Home address field, you should see the address pasted to the text editor.


The Top Level Folder is the container for all your phrases and scripts. You can assign a hotkey to it and call it up in any applications. To assign a hotkey, simply highlight the TopLevel Folder entry and click the Set button beside the Hotkey option. You can then choose the modifier key (Ctrl, Shift, Alt or Super) and the shortcut key.

After creating the top level folder, the next thing is to create a phrase or a script.
Phrase
The Phrase is a snippet of text that you use frequently. With a quick press of the shortcut key, you can quickly insert the phrase to the document that you are working at.
Go to File -> Create -> New Phrase. Enter the phrase content in the big text area and assign a shortcut key in the Hotkey option below.
Other than assigning hotkey, you can also use a abbreviation for the phrase. For example, I have set the abbreviation “mte” to the phrase “http://maketecheasier.com”. Now I just need to type “MTE” and it will automatically be replaced with the full URL.

Scripts
For those who have knowledge of scripting, you can add your script, assign a hotkey and get it to run anywhere else. For those who know nuts about scripting, the “Record Marco” function can help you to record simple keyboard events.

AutoKey is a desktop automation utility for Linux and X11. It allows you to create scripts and assign hotkeys to these scripts, allowing you to execute them on demand in whatever program you are using.
Compatibility with various distro and keyboard layout
Personally I did not test it on all the Linux distro and all the different keyboard layout. However, according to the developer of Autokey:The core part of AutoKey is sending and receiving keyboard events via the X server. It supports multiple X interfaces and should therefore be compatible with virtually any version of Linux running an X server. Full unicode support is provided and it should in theory work with any keyboard layout.Theoretically, it should work for all Linux distros and keyboard layout.
Installation
(the following installation instruction is based on Ubuntu)Open a terminal and type:
1 | sudo add-apt-repository ppa:cdekter/ppa |
2 | sudo apt-get update |
1 | sudo apt-get install autokey-gtk |
1 | sudo apt-get install autokey-qt |
Usage
Go to Applications -> Accessories -> Autokey.You will see on the left pane two folders named My Phrases and Sample Scripts. The My Phrases folder is binded to the hotkey “Ctrl + F7“.
To get a feel of the capability of Autokey, open a text editor and press Ctrl + F7, you should see the context menu with Address option. When you select the Home address field, you should see the address pasted to the text editor.
Usage: creating your own hotkey
To create your own hotkey, go to File -> Create -> New Top Level Folder.The Top Level Folder is the container for all your phrases and scripts. You can assign a hotkey to it and call it up in any applications. To assign a hotkey, simply highlight the TopLevel Folder entry and click the Set button beside the Hotkey option. You can then choose the modifier key (Ctrl, Shift, Alt or Super) and the shortcut key.
After creating the top level folder, the next thing is to create a phrase or a script.
Phrase
The Phrase is a snippet of text that you use frequently. With a quick press of the shortcut key, you can quickly insert the phrase to the document that you are working at.
Go to File -> Create -> New Phrase. Enter the phrase content in the big text area and assign a shortcut key in the Hotkey option below.
Other than assigning hotkey, you can also use a abbreviation for the phrase. For example, I have set the abbreviation “mte” to the phrase “http://maketecheasier.com”. Now I just need to type “MTE” and it will automatically be replaced with the full URL.
Scripts
For those who have knowledge of scripting, you can add your script, assign a hotkey and get it to run anywhere else. For those who know nuts about scripting, the “Record Marco” function can help you to record simple keyboard events.
Conclusion
For those who spend a lot of time on their keyboard, Autokey is a great tool to help you increase your productivity. Source: http://maketecheasier.comTuesday, September 28, 2010
Set up Samba for file-sharing
Samba, Apache, and MySQL are probably the biggest open source
projects found on Linux (aside from the Linux kernel itself, of course).
All three have really elevated Linux for use in home networks and
corporate environments.
With them, anyone can have a file and print server, a Web server, or a database. All three come with pretty much every Linux distribution you can find.
The most ubiquitous of the three is probably Samba, because it and the functionality it provides is found in every operating system. Linux, OS X, the BSDs and others use Samba. It is directly compatible with Windows because it uses the Windows file and print sharing protocols to allow for sharing Windows file systems on Linux and vice versa.
Samba allows for a lot of configuration, and there are many options to use — primarily relating to authentication. When Samba 4 finally lands, it will be an incredible release with Active Directory support and being able to act as an Active Directory server, with internal LDAP and Kerberos servers to fully flesh out what is necessary for full integration with Windows networks. Until then, you can still hack Samba up to do a lot of these things, and it works fantastic as a client in Windows networks. You can make Samba work with Active Directory, with LDAP, and with local passwords.
Most people will just want a stand-alone Samba server somewhere on their network and that is the easiest to set up. To begin with, you need Samba installed on your system. This can be done by installing the “samba” or “samba3″ (on some distributions) package, either using yum or apt-get or whatever mechanism your distribution uses to install packages. Once Samba is installed, edit the /etc/samba/smb.conf file. If you’re using Red Hat Enterprise Linux or Fedora, you will need to make further changes if you have SELinux support enabled; the comments in smb.conf will help with the additional steps.
A very basic smb.conf file will look like this:
The next step is to create the local passwords. Because Samba does not use the authentication credentials of the system (i.e., via PAM), you need to add the user to the Samba user database:
Once this is all complete, start the Samba server (or restart it):
This is the easiest way to set up Samba for file sharing. Other mechanisms exist for sharing files on a LAN, such as NFS or SSHFS, but Samba is quick, easy to set up, and reliable. It is also cross-platform, making it easy to share files amongst various operating systems. Source: http://blogs.techrepublic.com
With them, anyone can have a file and print server, a Web server, or a database. All three come with pretty much every Linux distribution you can find.
The most ubiquitous of the three is probably Samba, because it and the functionality it provides is found in every operating system. Linux, OS X, the BSDs and others use Samba. It is directly compatible with Windows because it uses the Windows file and print sharing protocols to allow for sharing Windows file systems on Linux and vice versa.
Samba allows for a lot of configuration, and there are many options to use — primarily relating to authentication. When Samba 4 finally lands, it will be an incredible release with Active Directory support and being able to act as an Active Directory server, with internal LDAP and Kerberos servers to fully flesh out what is necessary for full integration with Windows networks. Until then, you can still hack Samba up to do a lot of these things, and it works fantastic as a client in Windows networks. You can make Samba work with Active Directory, with LDAP, and with local passwords.
Most people will just want a stand-alone Samba server somewhere on their network and that is the easiest to set up. To begin with, you need Samba installed on your system. This can be done by installing the “samba” or “samba3″ (on some distributions) package, either using yum or apt-get or whatever mechanism your distribution uses to install packages. Once Samba is installed, edit the /etc/samba/smb.conf file. If you’re using Red Hat Enterprise Linux or Fedora, you will need to make further changes if you have SELinux support enabled; the comments in smb.conf will help with the additional steps.
A very basic smb.conf file will look like this:
[global]
workgroup = MYGROUP
server string = Samba Server Version %v
log file = /var/log/samba/log.%m
max log size = 50
security = user
passdb = tdbsam
[homes]
comment = Home Directories
browseable =no
writable = yesThis is an absolutely basic configuration file. If you already have a workgroup defined, change the “workgroup” value to whatever you have already defined for the network. The rest can remain as-is. This will allow you the ability to connect to the server and mount your home directory on the server from any other machine on the network.
The next step is to create the local passwords. Because Samba does not use the authentication credentials of the system (i.e., via PAM), you need to add the user to the Samba user database:
# smbpasswd -a userProvide the password for the user in question. Also note that this user must also exist on the system, so if this is a new user you must use useradd to create the user and passwd to set their password. If the user already exists on the server, there is no need to do anything more than set their Samba password.
Once this is all complete, start the Samba server (or restart it):
# service smb startNow, from another system, you can use smbclient to list available shares:
% smbclient -L \\server.myhost.com
Password:
Domain=[CERBERUS] OS=[Unix] Server=[Samba 3.5.4-62.fc13]
Sharename Type Comment
--------- ---- -------
IPC$ IPC IPC Service (Samba Server Version 3.5.4-62.fc13)
user Disk Home Directories
Domain=[CERBERUS] OS=[Unix] Server=[Samba 3.5.4-62.fc13]
Server Comment
--------- -------
Workgroup Master
--------- -------To mount the share, connect to \\server.myhost.com\user using the network browser in GNOME, the Finder in OS X, or Windows Explorer in Windows.
This is the easiest way to set up Samba for file sharing. Other mechanisms exist for sharing files on a LAN, such as NFS or SSHFS, but Samba is quick, easy to set up, and reliable. It is also cross-platform, making it easy to share files amongst various operating systems. Source: http://blogs.techrepublic.com
7 Linux sudo Command Tips and Tricks
Using sudo command, an user can execute root only commands.
In this article, let us review how to setup sudo environment along with some sudo command examples, tips, and tricks.
For example, if you want to edit the file /etc/group that can only be saved by root user, you typically do the following. When you do a :w, no problem, it will work, as it was opened using sudo command.
For example, umask is a bash built-in command, which will not work when used along with sudo as shown below.
In this article, let us review how to setup sudo environment along with some sudo command examples, tips, and tricks.
1. Set up sudo Environment in /etc/sudoers
You can provide sudo privilege to an individual user or a group by modifying /etc/sudoers.sudo access to an user
To provide sudo access to an individual user, add the following line to the /etc/sudoers file.sathiya ALL=(ALL) ALLIn the above example:
- sathiya : name of user to be allowed to use sudo
- ALL : Allow sudo access from any terminal ( any machine ).
- (ALL) : Allow sudo command to be executed as any user.
- ALL : Allow all commands to be executed.
sudo access to a group
To provide sudo access to a group, add the following line to the /etc/sudoers file.%programmers ALL=(ALL) ALLIn the above example:
- programmers : name of group to be allowed to use sudo. Group name should be preceded with percentage symbol.
- ALL : Allow sudo access from any terminal ( any machine ).
- (ALL) : Allow sudo command to be executed as any user.
- ALL : Allow all commands to be executed.
$ sudo cat /etc/sudoers %admin ALL=(ALL) ALL $ grep admin /etc/group admin:x:115:sathiya
2. Executing a command as super user
Once the sudo access is provided to your account in /etc/sudoers, you can pass any root command as an argument to the sudo command. For example, mount can only be done by root. But, a normal user can do mount as shown below using sudo.$ sudo mount /dev/sda3 /mntNote: If you are executing sudo for the first time in a shell it will ask for the password ( current user password ) by default.
3. Forgot to Use Sudo in Vim? No Worries. Save file Trick in vim with sudo
When you have opened a file that can be saved only by root user using vim (without using the sudo command), you can do the following.For example, if you want to edit the file /etc/group that can only be saved by root user, you typically do the following. When you do a :w, no problem, it will work, as it was opened using sudo command.
$ sudo vim /etc/group :wWhat if you’ve forgot to give sudo when you’ve opened the /etc/group file as shown below? In this case, instead of coming out of the file (and loosing all your changes) and executing the vim command with sudo, you can do the following.
$ vim /etc/group :w !sudo tee %Note: “:w !sudo tee %” will save the file as root privilege, even if you didn’t use sudo command to open it.
4. Forgot to give sudo for root command? Do it again using !!
If you’ve forgot to give sudo for a command that requires root privilege, instead of typing the command with sudo again, you can simply do sudo !! as shown below.$ head -n 4 /etc/sudoers head: cannot open `/etc/sudoers' for reading: Permission denied $ sudo !! sudo head -n 4 /etc/sudoers # /etc/sudoers # # This file MUST be edited with the 'visudo' command as root. #
5. Get Root Shell Access using Sudo
To get a root shell from your user account, do the following.$ sudo bashOnce you get the root shell, you can execute any root command without having to enter sudo in front of it every time.
6. Built in commands won’t work with Sudo – Command not found
sudo invokes an executable as the another user, so bash built in commands won’t work. It will give “sudo command not found” error as shown below.For example, umask is a bash built-in command, which will not work when used along with sudo as shown below.
$ sudo umask sudo: umask: command not foundWork-around: To use bash shell built-in command in sudo, first get the root shell, by doing ‘sudo bash’ and then execute the shell built in command.
7. View Unauthorized Sudo command executions from auth.log
When an user who doesn’t have sudo permission, tries to execute sudo command, they’ll get following error message.$ sudo ls / [sudo] password for test: raj is not in the sudoers file. This incident will be reported.Anytime this happens, it will be logged in the /var/log/auth.log file for sysadmins to view any unauthorized sudo access.
Sep 25 18:41:35 sathiya sudo: raj : user NOT in sudoers ; TTY=pts/4 ; PWD=/home/raj ; USER=root ; COMMAND=/bin/ls /
Source: http://www.thegeekstuff.com
Tuesday, August 10, 2010
AHK script for translating MemoQ segment with GT4T
Here is a script written in AHK for translating entire segments in MemoQ with the help of Google Translate by means of the program GT4T (http://gt4t.net/gt4t_en/). The script assumes that you have mapped the key combination ALT+J to translate the selected words in GT4T, but of course this could be changed accordingly. Just press ALT+X and the segment will be translated via Google Translate.
; Memoq
SendMode Input
!x::
Send ^+s
Sleep, 150
Send ^a
Sleep, 150
Send !j
return
; Memoq
SendMode Input
!x::
Send ^+s
Sleep, 150
Send ^a
Sleep, 150
Send !j
return
Sunday, August 8, 2010
Translating SDL Trados projects in memoQ
SDL Trados is one of the
more popular translation tools besides memoQ. memoQ provides
interoperability with SDL Trados 2007 and SDL Trados Studio 2009.Using
memoQ you can accept jobs in SDL Trados Tageditor’s TTX format or SDL
Trados Translator’s Workbench’s bilingual DOC/RTF format. SDL Trados
2007 does not accept all segmentation and can crash on files segmented
by other translation tools, therefore prior to opening a file it is
advised to pre-segment the file using a demo or paid-up version of SDL
Trados 2007. You can do this by opening Translator’s Workbench, creating
or opening an empty translation memory, clicking Tools/Translate and
enabling the Segment unknown sentences checkbox, then running a
pre-translation. If you don’t pre-segment the files, memoQ will import
an empty file by default. You can click Add document as and select
Import unsegmented content, however, be careful with this - we cannot
guarantee that SDL Trados will accept the file translated this way.
Thousands of translators and companies are using memoQ to process SDL
Trados jobs. Many language service providers are using the memoQ server
to add teamwork capabilities while translating SDL Trados jobs. This is a
reliable solution.
Translation memories from SDL Trados can be imported in TMX format. If you use TMX 1.4b, and your translation memories come from a tagged document such as HTML or XML, memoQ will also perform a tag conversion which goes beyond what’s described in the standard. This tag conversion is specifically targeted at converting SDL Trados tags into memoQ tags.
memoQ, just like SDL Trados Studio 2009, supports XLIFF as a bilingual format, and the two systems are interoperable through XLIFF. You cannot export a memoQ file in SDL Trados Studio 2009 into the underlying format such as Microsoft Word, and you cannot export an SDLXLIFF file in memoQ into Microsoft Word either.
In a server scenario you cannot expect memoQ to connect to an SDL Trados server. Server technologies are, unfortunately, not interoperable. This is, however, a rare scenario and most translation companies are not expected to translate online.
memoQ-prepared projects can also be processed by SDL Trados 2007 and SDL Trados Studio 2009 through XLIFF. Source: kilgray.com
Translation memories from SDL Trados can be imported in TMX format. If you use TMX 1.4b, and your translation memories come from a tagged document such as HTML or XML, memoQ will also perform a tag conversion which goes beyond what’s described in the standard. This tag conversion is specifically targeted at converting SDL Trados tags into memoQ tags.
memoQ, just like SDL Trados Studio 2009, supports XLIFF as a bilingual format, and the two systems are interoperable through XLIFF. You cannot export a memoQ file in SDL Trados Studio 2009 into the underlying format such as Microsoft Word, and you cannot export an SDLXLIFF file in memoQ into Microsoft Word either.
In a server scenario you cannot expect memoQ to connect to an SDL Trados server. Server technologies are, unfortunately, not interoperable. This is, however, a rare scenario and most translation companies are not expected to translate online.
memoQ-prepared projects can also be processed by SDL Trados 2007 and SDL Trados Studio 2009 through XLIFF. Source: kilgray.com
memoQ and bilingual DOC
Unclean, shmunclean, Add document, Import/update
bilingual – read the whole story behind memoQ’s support for bilingual
DOC files.
If you’re confused and not sure which command to use when working with bilingual RTF/DOC files, you are probably not alone. In this post we explain how memoQ supports this file format.
We designed this feature with interoperability in mind. There are two distinct scenarios that memoQ supports.
Scenario 1: A memoQ-based workflow where a third-party tool is used to translate or proofread a document, but the original file is imported into a memoQ project. This workflow is made up of the following steps:
Good to know: When you update your project using a from DOC, memoQ recognizes which target segments were edited in the file. These rows will always become “Edited” in your project, which gives you an easy way to quickly review changes.
Scenario 2: A Trados or Wordfast-based workflow where memoQ is used to receive and deliver a job in the other tool’s format.
If you’re confused and not sure which command to use when working with bilingual RTF/DOC files, you are probably not alone. In this post we explain how memoQ supports this file format.
We designed this feature with interoperability in mind. There are two distinct scenarios that memoQ supports.
Scenario 1: A memoQ-based workflow where a third-party tool is used to translate or proofread a document, but the original file is imported into a memoQ project. This workflow is made up of the following steps:
- Import any document into a memoQ project.
- Select the document, click Export bilingual, and select TRADOS-compatible bilingual DOC. In the options, make sure Simple formatting is checked.
- Edit the document in Word or any CAT tool that supports the bilingual DOC format.
- Back in memoQ, use Import/update bilingual to update the document in your project. memoQ will recognize that the file is identical to a document in your project, and update that document’s target segments with what it finds in the DOC file.
Good to know: When you update your project using a from DOC, memoQ recognizes which target segments were edited in the file. These rows will always become “Edited” in your project, which gives you an easy way to quickly review changes.
Scenario 2: A Trados or Wordfast-based workflow where memoQ is used to receive and deliver a job in the other tool’s format.
- Make sure you start with an “unclean” file, i.e., a document that has been pre-translated in Trados or Wordfast.
- Simply use Add document to import the document into your memoQ project.
- To export an “unclean” file that contains both the source (as hidden text) and your translations, use Export bilingual. Choose TRADOS-compatible bilingual DOC, and make sure Simple formatting is not checked.
- To export a “clean” Word document with only the translated text, use Export (dialog) or Export (stored path).
Saturday, August 7, 2010
How to connect to SkyDrive with WebDAV
Actually, I stumbled upon this when I decided to try out Office 2010
beta. I haven’t found any official documentation about how to connect to
Windows Live SkyDrive with WebDAV (or any API),
so I’m not sure how well supported this will be in the future. If you
find any word about this from Microsoft, please let me know in the
comments. The good news is that it works. The bad news is that it is
very slow, but being 25 GB for free I guess you get what you pay for
speed-wise (understandably).
[Update: New info about a tool I wrote to find out the addresses for WebDAV discussed below]
There is now a tool available that can determine the addresses you need for your WebDAV access to SkyDrive. It is available on CodePlex here. You can download the console application and run it from a command line. There is also a WPF application (seen below) if you have the latest version of .NET 3.5 SP1. More info in CodePlex site. But read the background below to know how I got there and what to do with the information that the tool provides.

But let me start at the beginning with a brief introduction to Office 2010 beta. If you find this boring, scroll down to here.
The application I’ve missed the most is probably Outlook. At the same time it is the application where the hate/love relationship is the greatest. I really like working with it but at the same time it feels way too big, bulky and complex for something that should be simple: mail and calendar (the way I see it). Too much MAPI baggage I think.
Then I listened to Windows Weekly with Paul Thurrott about a new installation option for Office 2010 beta. It is called Click-To-Run and sounded interesting since it uses an application virtualization technology called App-V that means that you can install and run the application side by side with whatever you have on your computer without risking changing any system settings (which especially affects Outlook, had I had Outlook 2007 installed).
I decided to give Office 2010 an extra chance and now I’m glad I did. Not only for discovering WebDAV access to SkyDrive. Everyone can download, install and use Office 2010 beta until october 2010 when it expires, but you do need a Windows Live ID.
Of course, there are a hundred-and-one SKUs (different packing of included applications etc) to choose from for Office 2010 also. No, I shouldn’t be so sarcastic about that since it does mean that if you don’t need everything in the full suite you will be able to get it for a lower price. But it is a pain to keep track of all the combinations.
What I’m getting to is that Click-To-Run only seems to be available for the “Home and Business” SKU, at least during the beta period. So go and download and install it here (requires registration via a Windows Live ID). The installation experience was smooth but a little weird. You see, Click-To-Run also has some sort of streaming built in so that different parts are downloaded when needed. In practice this meant that it looked as though only PowerPoint was installing since that was the screen shown during most of the installation. But I realized that was because an introductory PPT-file is automatically shown as the first thing after installation. Also, beware that one (or two?) dialogs didn’t activate as the topmost window and therefore I missed answering them (which is why the installation seemed to be stuck for a while).
One great thing about configuring Outlook 2010 that really impressed me was that I only had to specify my e-mail address for Outlook to figure out on which server my mail was located and by which access method it could connect. Maybe I shouldn’t be impressed since it usually is that easy for ordinary POP3/IMAP access, but still – a great improvement that has awakened my interest in Microsoft Office.
Another thing I like already is that the big circle button in the top left corner of the window is gone and has been replaced by a File tab (albeit a “special” tab) . That makes the interface much more uniform – a strip of tabs – and maybe even I can find the ribbon likable…
Paul Thurrott mentioned this feature in the netcast and it was the first thing I tried. Under the File tab and the Share menu option you’ll find “Save to SkyDrive”. Of course, I assume you already have a SkyDrive account so just login and you will be presented with your folders.

The next step in this screen dump is to double click the Public folder. Note however that this is really slow (for me, at least) and that Excel is unresponsive for a minute or two. Lets hope we can attribute this to beta software. Have patience, and you will (hopefully) be prompted with a dialog box to specify the file name, which is also what gave the WebDAV functionality away.

Also, before this dialog box appeared, the status bar gave away an address. I have removed the part that is unique to every user below (a guid), and changed it in the screen dump above.

Nice! My conclusion was that Office 2010 must be using WebDAV for this so I had to investigate this further.
Another surprise was that SkyDrive in the browser will obviously support Office Web Applications, which means that you can view and even edit the documents right there in your favorite browser (which is Firefox, of course). At the moment, you can only view Word documents, but you can actually edit Excel spreadsheets. Excel editing looks really nice and is really hard to separate from the real application visually, however it does not seem to have a lot of functionality. I couldn’t find copy-down for instance. It remains to be seen just how much functionality will be available, but it would be strange if Microsoft didn’t try to at least match Google Docs Spreadsheets.
[Update: I first thought that you could access SkyDrive folders without the sub domain mentioned above. That is probably not the case, so I've revised my instructions.]
In order to determine what path to specify in Windows when connecting via WebDAV, you either need to run my tool or use Office 2010. If using Office 2010, create a document and share it to SkyDrive as described above. When saving the document and specifying its file name, you have the chance to look at the address bar and copy the path, in my example:
https://pxeptc.docs.live.net/b8c6f2e973a17512/^2Public
Actually, the folder name “b8c6f2e973a17512″ in the path is the same as a personal sub domain when logging on to SkyDrive the normal way from your web browser. It can look like “http://cid-b8c6f2e973a17512.skydrive.live.com/”.
The sub domain “pxeptc” in my example is something derived from your SkyDrive account and the specific SkyDrive folder you want to access via WebDAV. So for every folder in SkyDrive that you want to access via WebDAV, you have to share a document from inside Office 2010 to determine this name.
In developing my tool, I saw that Office calls a web service to determine the WebDAV addresses for each folder in your SkyDrive account. That web service is located at http://docs.live.net/SkyDocsService.svc but you can’t access it in your browser since it requires a Live ID authentication token. (My tool fixes that.)
Also, some folders are special and “known” to the system much like “My Documents” on your computer. That means that their name is not the same as on the web page in SkyDrive. I have identified two such folders that I have. In SkyDrive they are called “Public” and “My Documents”, but in WebDAV they are called “^2Public” and “^2Documents”.
Also note that Windows recognize another way to specify this address which I think is interpreted in the same way. So the following two addresses would be equivalent:
https://pxeptc.docs.live.net/b8c6f2e973a17512/^2Public
\\pxeptc.docs.live.net@SSL\b8c6f2e973a17512\^2Public
To increase speed you should also make sure the following option is unchecked in Windows (if you don’t need it):
Control Panel, Internet Options, Connections, LAN Settings, Automatically detect settings
Also, it is very slow. Sure, you get what you pay for, but maybe there will be more (payment) options with SkyDrive in the future now that the sharing functionality from Office 2010 has been implemented. I don’t think I would mind paying if the speed was there.
I suspect Microsoft has something up their sleeve when it comes to “storage drives in the cloud” (duh! ). Right now they have been silent for quite some time. I use another service, namely Live Mesh,
for file synchronization. It works great (5 GB limit), but it has been
in beta for long now and Microsoft has discontinued all the developer
stuff (sdks) for that service and for all or most of Live Services also I
think. They are obviously up to something.
). Right now they have been silent for quite some time. I use another service, namely Live Mesh,
for file synchronization. It works great (5 GB limit), but it has been
in beta for long now and Microsoft has discontinued all the developer
stuff (sdks) for that service and for all or most of Live Services also I
think. They are obviously up to something.
Unfortunately, there is no caching of files accessed over WebDAV. Windows has a built in system for remote access of files on remote locations called “Offline files”, but it only works on true Windows paths (SMB) and not WebDAV. At least not that I know of. Therefore you probably want to save to local disk and use a synchronization application to put your files on SkyDrive.
For me as a developer the most important part of this story is that there now is an api for SkyDrive access where there was none previously. Not counting the screenscraping way of the SkyDrive client library by ghollosy on Codeplex. It worked great when I tried it, but I don’t like to be in the hands of the web browser user interface on the site in case that changes (more of a “when”, than “if”?).
Anyway, I also discovered that this WebDAV access works with photos but I haven’t found a way to determine the sub domain needed for all my photo folders. However, if you have the name of a photo folder, I got Windows Explorer to do a redirect and tell me the name.
I just followed the pattern above and replaced the last part such as “^2Documents” with the exact name of one of my photo folders. And what do you know? Windows Explorer took a few seconds but then redirected to a sub domain under docs.live.net and there were all my photos in that folder!
First, right-click on Network icon in Windows Explorer and select “Map network drive…”.

This dialog box will be shown:

[Update: I previously had several screen dumps here, going through the whole wizard, but I later found out that as long as you map a drive letter at the same time, you can do it all from this single dialog box.]
Type in the path to the SkyDrive folder that you want access to in the “Folder” field. You can use either the https path or the \\ path. For instance:
\\pxeptc.docs.live.net@SSL\DavWWWRoot\b8c6f2e973a17512\^2Documents

Windows will ask for your SkyDrive login either way, but you should also check the option “Connect using different credentials”. You don’t have to check “Reconnect at logon” of course, but then you have to remember the path the next time you need access. It may be a bit irritating to have the SkyDrive mapped on every boot since Windows probably will complain that it could not attach the mapped drive (if you don’t store the password permanently).
Click Finish and after typing your SkyDrive user name and password you are done.


Remember that file access to a remote location using WebDAV probably is a lot slower than local file access in all cases, and especially slow on SkyDrive. Don’t be surprised if your waiting time increases when saving files etc. Source: http://www.mikeplate.com
[Update: New info about a tool I wrote to find out the addresses for WebDAV discussed below]
There is now a tool available that can determine the addresses you need for your WebDAV access to SkyDrive. It is available on CodePlex here. You can download the console application and run it from a command line. There is also a WPF application (seen below) if you have the latest version of .NET 3.5 SP1. More info in CodePlex site. But read the background below to know how I got there and what to do with the information that the tool provides.

But let me start at the beginning with a brief introduction to Office 2010 beta. If you find this boring, scroll down to here.
Microsoft Office 2010 and installing the beta
I had actually decided to part from Microsoft Office in favor of more lightweight applications like Google Docs and OpenOffice. For two reasons: price and size. So I haven’t installed Office 2007 on any of my newer computers or laptops for the last six months or so in order to ensure that I don’t need it anymore and I have gotten by pretty well.The application I’ve missed the most is probably Outlook. At the same time it is the application where the hate/love relationship is the greatest. I really like working with it but at the same time it feels way too big, bulky and complex for something that should be simple: mail and calendar (the way I see it). Too much MAPI baggage I think.
Then I listened to Windows Weekly with Paul Thurrott about a new installation option for Office 2010 beta. It is called Click-To-Run and sounded interesting since it uses an application virtualization technology called App-V that means that you can install and run the application side by side with whatever you have on your computer without risking changing any system settings (which especially affects Outlook, had I had Outlook 2007 installed).
I decided to give Office 2010 an extra chance and now I’m glad I did. Not only for discovering WebDAV access to SkyDrive. Everyone can download, install and use Office 2010 beta until october 2010 when it expires, but you do need a Windows Live ID.
Of course, there are a hundred-and-one SKUs (different packing of included applications etc) to choose from for Office 2010 also. No, I shouldn’t be so sarcastic about that since it does mean that if you don’t need everything in the full suite you will be able to get it for a lower price. But it is a pain to keep track of all the combinations.
What I’m getting to is that Click-To-Run only seems to be available for the “Home and Business” SKU, at least during the beta period. So go and download and install it here (requires registration via a Windows Live ID). The installation experience was smooth but a little weird. You see, Click-To-Run also has some sort of streaming built in so that different parts are downloaded when needed. In practice this meant that it looked as though only PowerPoint was installing since that was the screen shown during most of the installation. But I realized that was because an introductory PPT-file is automatically shown as the first thing after installation. Also, beware that one (or two?) dialogs didn’t activate as the topmost window and therefore I missed answering them (which is why the installation seemed to be stuck for a while).
One great thing about configuring Outlook 2010 that really impressed me was that I only had to specify my e-mail address for Outlook to figure out on which server my mail was located and by which access method it could connect. Maybe I shouldn’t be impressed since it usually is that easy for ordinary POP3/IMAP access, but still – a great improvement that has awakened my interest in Microsoft Office.
Another thing I like already is that the big circle button in the top left corner of the window is gone and has been replaced by a File tab (albeit a “special” tab) . That makes the interface much more uniform – a strip of tabs – and maybe even I can find the ribbon likable…
Microsoft Office 2010 and the web
The first thing that interested me, and that led to the discovery of WebDAV for SkyDrive was “Save to SkyDrive”. Yes I know – get to the point!! – not yet…Paul Thurrott mentioned this feature in the netcast and it was the first thing I tried. Under the File tab and the Share menu option you’ll find “Save to SkyDrive”. Of course, I assume you already have a SkyDrive account so just login and you will be presented with your folders.
The next step in this screen dump is to double click the Public folder. Note however that this is really slow (for me, at least) and that Excel is unresponsive for a minute or two. Lets hope we can attribute this to beta software. Have patience, and you will (hopefully) be prompted with a dialog box to specify the file name, which is also what gave the WebDAV functionality away.

Also, before this dialog box appeared, the status bar gave away an address. I have removed the part that is unique to every user below (a guid), and changed it in the screen dump above.
Nice! My conclusion was that Office 2010 must be using WebDAV for this so I had to investigate this further.
Another surprise was that SkyDrive in the browser will obviously support Office Web Applications, which means that you can view and even edit the documents right there in your favorite browser (which is Firefox, of course). At the moment, you can only view Word documents, but you can actually edit Excel spreadsheets. Excel editing looks really nice and is really hard to separate from the real application visually, however it does not seem to have a lot of functionality. I couldn’t find copy-down for instance. It remains to be seen just how much functionality will be available, but it would be strange if Microsoft didn’t try to at least match Google Docs Spreadsheets.
Steps to access SkyDrive folders with WebDAV in Windows Explorer
So, with this new information, here are the steps to connect to SkyDrive folders using WebDAV and get access to their contents in Windows Explorer. Note that I’m using Windows 7 (64-bit) and I don’t know if this works in older Windows versions.[Update: I first thought that you could access SkyDrive folders without the sub domain mentioned above. That is probably not the case, so I've revised my instructions.]
In order to determine what path to specify in Windows when connecting via WebDAV, you either need to run my tool or use Office 2010. If using Office 2010, create a document and share it to SkyDrive as described above. When saving the document and specifying its file name, you have the chance to look at the address bar and copy the path, in my example:
https://pxeptc.docs.live.net/b8c6f2e973a17512/^2Public
Actually, the folder name “b8c6f2e973a17512″ in the path is the same as a personal sub domain when logging on to SkyDrive the normal way from your web browser. It can look like “http://cid-b8c6f2e973a17512.skydrive.live.com/”.
The sub domain “pxeptc” in my example is something derived from your SkyDrive account and the specific SkyDrive folder you want to access via WebDAV. So for every folder in SkyDrive that you want to access via WebDAV, you have to share a document from inside Office 2010 to determine this name.
In developing my tool, I saw that Office calls a web service to determine the WebDAV addresses for each folder in your SkyDrive account. That web service is located at http://docs.live.net/SkyDocsService.svc but you can’t access it in your browser since it requires a Live ID authentication token. (My tool fixes that.)
Also, some folders are special and “known” to the system much like “My Documents” on your computer. That means that their name is not the same as on the web page in SkyDrive. I have identified two such folders that I have. In SkyDrive they are called “Public” and “My Documents”, but in WebDAV they are called “^2Public” and “^2Documents”.
Also note that Windows recognize another way to specify this address which I think is interpreted in the same way. So the following two addresses would be equivalent:
https://pxeptc.docs.live.net/b8c6f2e973a17512/^2Public
\\pxeptc.docs.live.net@SSL\b8c6f2e973a17512\^2Public
To increase speed you should also make sure the following option is unchecked in Windows (if you don’t need it):
Control Panel, Internet Options, Connections, LAN Settings, Automatically detect settings
Conclusions
That’s it! Of course the maximum size of a single file is still enforced (I just had to try…). Unfortunately I don’t think this will work in other operating systems. I assume that the WebDAV part is used according to the standard, so that should not be a problem. However, I did notice when looking closer at the http communication that the server wants to authenticate with Passport1.4 (MS-PASS) which is Microsoft specific and I doubt that would work on Mac or Linux?Also, it is very slow. Sure, you get what you pay for, but maybe there will be more (payment) options with SkyDrive in the future now that the sharing functionality from Office 2010 has been implemented. I don’t think I would mind paying if the speed was there.
I suspect Microsoft has something up their sleeve when it comes to “storage drives in the cloud” (duh!
). Right now they have been silent for quite some time. I use another service, namely Live Mesh,
for file synchronization. It works great (5 GB limit), but it has been
in beta for long now and Microsoft has discontinued all the developer
stuff (sdks) for that service and for all or most of Live Services also I
think. They are obviously up to something.Unfortunately, there is no caching of files accessed over WebDAV. Windows has a built in system for remote access of files on remote locations called “Offline files”, but it only works on true Windows paths (SMB) and not WebDAV. At least not that I know of. Therefore you probably want to save to local disk and use a synchronization application to put your files on SkyDrive.
For me as a developer the most important part of this story is that there now is an api for SkyDrive access where there was none previously. Not counting the screenscraping way of the SkyDrive client library by ghollosy on Codeplex. It worked great when I tried it, but I don’t like to be in the hands of the web browser user interface on the site in case that changes (more of a “when”, than “if”?).
Additional information about photos
In my SkyDrive account I also have photos. They are obviously not exactly the same thing as a folder. I think they are somehow integreated with Windows Live Photos or whatever the branding is. Maybe you can have Windows Live Photos in your Windows Live account without having a SkyDrive folder account?Anyway, I also discovered that this WebDAV access works with photos but I haven’t found a way to determine the sub domain needed for all my photo folders. However, if you have the name of a photo folder, I got Windows Explorer to do a redirect and tell me the name.
I just followed the pattern above and replaced the last part such as “^2Documents” with the exact name of one of my photo folders. And what do you know? Windows Explorer took a few seconds but then redirected to a sub domain under docs.live.net and there were all my photos in that folder!
How to set up WebDAV in Windows Explorer
If you need more specifics about how to create the WebDAV connection in Windows Explorer, here are the screendumps.First, right-click on Network icon in Windows Explorer and select “Map network drive…”.

This dialog box will be shown:

[Update: I previously had several screen dumps here, going through the whole wizard, but I later found out that as long as you map a drive letter at the same time, you can do it all from this single dialog box.]
Type in the path to the SkyDrive folder that you want access to in the “Folder” field. You can use either the https path or the \\ path. For instance:
\\pxeptc.docs.live.net@SSL\DavWWWRoot\b8c6f2e973a17512\^2Documents

Windows will ask for your SkyDrive login either way, but you should also check the option “Connect using different credentials”. You don’t have to check “Reconnect at logon” of course, but then you have to remember the path the next time you need access. It may be a bit irritating to have the SkyDrive mapped on every boot since Windows probably will complain that it could not attach the mapped drive (if you don’t store the password permanently).
Click Finish and after typing your SkyDrive user name and password you are done.


Remember that file access to a remote location using WebDAV probably is a lot slower than local file access in all cases, and especially slow on SkyDrive. Don’t be surprised if your waiting time increases when saving files etc. Source: http://www.mikeplate.com
Saturday, July 3, 2010
LIMBA ROMÂNĂ ÎN EPOCA INFORMATICII
|
Limbajul scris sau vorbit este singura
modalitate de materializare a gindirii noastre discursive, cea care
se
bazeaza pe enunturi pentru a exprima conceptia noastra despre lume.
El se impleteste cu procesul
de gindire si are ca scop sa "cristalizeze" produsul acesteia si sa
il
"traduca" in asa fel incit sa fie inteles si de alte persoane. Cu
ajutorul
limbajului gindirea umana isi pierde caracterul ei inefabil si trece
printr-un proces de sublimare al carei rezultat este cuvintul scris
sau
vorbit. Scopul limbajului este de a facilita comunicarea interumana
pentru
ca oamenii sa poata sa schimbe intre ei cunostinte, experiente de
viata si
orice alt tip de informatii care ii ajuta sa evolueze si sa
inteleaga mai
bine mediul in care traiesc. Pe scurt, rolul principal al limbajului
este sa
realizeze transmiterea rapida si mai ales corecta a unor enunturi
care sint
produsul gindirii.
Limba se
afla permanent intr-un proces de evolutie, ce poate fi mai usor de
inteles
daca il asemanam cu ciclul evolutiv al unui specii de fiinte vii,
care are in
principal trei etape si anume : formare, dezvoltare, stabilizare,
disparitie (extinctie
sau transformare).
Evolutia unei limbi se desfasoara foarte lent, pe perioade de timp
de
ordinul sutelor de ani, dar etapele mentionate mai inainte
caracterizeaza
evolutia majoritatii limbilor care au fost in uz de-a lungul
timpului in
diferite parti ale globului. Cele mai multe limbi folosite in
timpurile
vechi au
disparut complet, insa exista limbi care desi nu mai sint vorbite in
mod curent
(de ex. latina), evolutia lor finala este mai degraba o
transformare decit o extinctie, pentru ca ele au dat nastere la alte
limbi
care le pastreaza caracteristicile principale. Limbile care sint
folosite in prezent nu au nici ele garantata "supravietuirea" pe
termen nedefinit. Limba româna deriva din limba latina populara la care s-au adaugat de-a lungul timpului cuvinte provenite din limbile popoarelor cu care românii au venit in contact economic sau militar (slavona - rusa veche, turca, greaca, bulgara, maghiara, germana, albaneza, etc.). Exista inca multe semne de intrebare asupra modului in care a fost posibil ca o populatie straina (colonistii romani) in numar relativ mic a reusit sa isi impuna limba unei mase mult mai mari de oameni, in speta dacilor, care erau populatia bastinasa si aveau o limba proprie de origine tracica. Originea latina a limbii române nu poate fi pusa la indoiala pentru ca sistemul gramatical (structura de rezistenta a oricarei limbi) provine din latina, la fel ca si majoritatea cuvintelor. Limba româna a avut de la formarea ei o evolutie naturala, care a dus pe de o parte la individualizarea (separarea) precisa a ei in cadrul grupului principalelor limbi romanice (franceza, italiana, spaniola, portugheza), iar pe de alta parte la formarea de dialecte caracteristice grupurilor mari populationale din Transilvania, Moldova si Muntenia. Limba româna a trecut deci de la formarea sa printr-un un proces de stabilire a unei identitati proprii in cadrul grupului de limbi provenite din latina, proces completat la interiorul limbii de un fenomen de diferentiere relativa a limbii vorbite in provinciile istorice românesti. Evolutia limbii române nu s-a oprit, din contra, ea continua cu eforturile permanente pe care le face limba pentru a se moderniza, in conditiile in care trebuie sa se adapteze la tendintele de uniformizare a experientei existentiale umane reflectate in conceptul de globalizare. Modul in care limba româna va reusi sa tina pasul cu modernizarea fara a-si pierde identitatea ei specifica va fi definitoriu pentru existenta sa viitoare. |
|
Pentru a intelege mai bine modul de
raspuns al
limbii române la diversele influente putem apela la o analogie.
Orice organism viu (indiferent de gradul
sau de complexitate) se afla intr-un proces permanent de schimb de
materie si
energie cu mediul inconjurator, schimb care are loc in ambele
sensuri,
dinspre mediu catre organism si dinspre organism catre mediu.
Organismul respectiv este nevoit sa preia din
mediul inconjurator substantele si energia care ii sint necesare
pentru supravietuire si
sa le prelucreze in asa fel incit ele sa poata fi asimilate
(adaugate la
structura sa interna) sau transformate in energie necesara
proceselor
interne. In paralel cu acest proces de asimilare are loc si procesul
invers,
de transfer de materie si energie dinspre organism spre mediul
ambiant.
Strategia de supravietuire a oricarei fiinte presupune insa un
control strict
asupra schimbului de resurse cu mediul inconjurator, pentru a evita
ca
structura interna sa îi fie afectata in mod negativ,
ceea ce ar avea ca rezultat mai devreme sau mai tirziu dezintegrarea
organismului respectiv. Schimbul de resurse este mentinut deci la un
nivel
calitativ si cantitativ care sa aiba ca rezultat intarirea
structurii
interne a organismului, ceea ce va permite supravietuirea sa in
conditii
optime. Toate fiintele vii poseda niste mecanisme de prezervare a
integritatii structurii
lor interne, mecanisme care sint reunite sub titulatura de "sistem
imunitar". Atunci cind acesta deceleaza prezenta unui "corp strain"
(microb,
virus, etc.) in organism sint declansate automat mai multe cai de
neutralizare a lui, in asa fel incit sa nu se ajunga la situatia ca
acest
corp strain sa pericliteze strarea de echilibru (sanatate) a
organismului
respectiv.
Limba unui popor trebuie
sa se adapteze permanent la conditiile mediului socio-politic,
economic si
cultural in care traieste populatia ce vorbeste limba respectiva. O
limba
"vie" (folosita in mod curent de o populatie formata dintr-un numar
apreciabil de persoane) nu se afla niciodata intr-o stare de
"incremenire",
influentele asupra ei venind atit dinspre interior cit si dinspre
exterior.
Astfel, oamenii care vorbesc o anumita limba au nevoie de cuvinte
care sa
exprime realitatile specifice perioadei istorice in care traiesc si
pentru
aceasta ei aleg sa inventeze cuvinte noi sau din contra preiau
cuvinte din
alte limbi. Situatia optima din punct de vedere al dezvoltarii
limbii este
caracterizata de o stare de echilibru intre influentele interne si
cele
externe, adica intre crearea de cuvinte noi si adoptarea de
neologisme.
Procesul de adaptare trebuie sa duca insa la intarirea limbii
respective si
nu la distrugerea ei. La fel ca in cazul unui organism viu,
pastrarea
nealterata a structurii interne a limbii reprezinta cheia care ii va
permite
sa supravietuiasca si sa prospere, chiar si in situatia in care este
supusa
la influente externe extrem de importante.
Innoirea vocabularului unei limbi este un proces esential si inevitabil, in conditiile schimbarilor (stiintifice, tehnologice, sociale, etc.) care au loc permanent in societatea umana. Adoptarea de neologisme trebuie insa sa se faca dupa un model bine pus la punct, in asa fel incit cuvintele nou introduse sa fie asimilate perfect, nu sa fie inglobate cu forta in limba importatoare, si sa apara grotesc, ca niste corpi straini care intretin niste rani deschise. Un cuvint strain trebuie deci adaptat conditiilor specifice ale limbii române pentru a-l include in vocabular. Oricit de frumos (melodios) ar suna un anumit neologism, includerea in vocabularul român trebuie sa depinda in principal de modul in care el se integreaza in limba, deci de cit de bine poate fi facut sa respecte regulile gramaticale ale limbii române. Din aceasta cauza acceptarea unui potential neologism trebuie decisa luind in consideratie in principal criteriile functionale (de ex. cit de bine se poate declina cuvintul) si nu pe acelea estetice (de ex. cit de bine ne încîntă auzul). Una din caracteristicile principale ale limbii române este reprezentata de caracterul ei fonetic, care se defineste printr-o corespondenta exacta intre pronuntarea cuvintelor si scrierea lor. Atita timp cit caracterul fonetic al limbii este pastrat intact limba romana va supravietui si va prospera. In cazul unei fiinte vii influentele externe sint reprezentate de energie si de materie. Dar acestea se intilnesc si in cazul limbii, unde energia poate fi asimilata cu influentele culturale, iar materia cu vocabularul propriu-zis (cuvintele folosite in mod curent). Este evident ca influenta culturala determina modul de constituire a cuvintelor noi. In cazul unui popor care are incredere in cultura sa si nu o socoteste inferioara altor culturi, majoritatea cuvintelor noi vor fi create pornind de la cuvinte deja existente in limba respectiva sau prin inventarea lor. Acesta este cazul popoarelor anglo-saxone. In cazul unui popor care are un sentiment de inferioritate d.p.d.v. cultural va exista tendinta ca importul de cuvinte sa fie masiv, pentru ca lipseste sentimentul de incredere in fortele proprii. Acesta este cazul poporului român, dar si al altor popoare mai mici. Avem de-a face cu un cerc vicios care va avea ca rezultat in ultima instanta disparitia culturii si a limbii române sau transformarea lor in surogate ale culturii si limbii majoritare, care in acest moment este cea anglo-saxona. |
|
Imbogatirea fondului lexical al limbilor
s-a
facut multa vreme in principal prin crearea de cuvinte noi (fie
inventindu-le, fie derivindu-le din cuvinte deja existente), iar in
mod
secundar prin importul de cuvinte din limbile vorbite de populatiile
vecine.
In ziua de azi, poate si din cauza globalizarii, crearea de cuvinte
noi a
fost aproape complet abandonata, la fel si importul de cuvinte din
limbile
vecine, preferindu-se o varianta mult mai comoda, aceea de importare
a
cuvintelor dorite din limba care este cel mai aproape de statutul de
limba
universala (engleza) sau din alta limba de circulatie
internationala (eventualitate mult mai rara).
Este greu de spus ce ii
face pe români sa prefere situatia de importatori de cuvinte,
aceleia de
creatori de cuvinte. Sa fie vorba de complexul "provincialului",
care
doreste sa isi depaseasca conditia, dar pentru ca nu poate realiza
acest
lucru in mod practic (prin emigrare imediata), incearca macar sa se
transporte "simbolic" in interiorul societatii in care viseaza sa
isi
desfasoare existenta? Din pacate multi dintre acei români care pot
fi
definiti ca niste "artisti ai cuvintelor", in speta scriitorii
profesionisti, se incadreaza din ce in ce mai mult in curentul
general si
rateaza ocazia de a imbogati vocabularul limbii române cu creatiile
lor
personale, preferind sa devina niste mesageri (colportori) care
incetatenesc (legitimeaza) uzul unor cuvinte, uneori extrem de
nefericite,
preluate din engleza, in defavoarea unor cuvinte de origine româna.
Reticenta românilor in a deveni fauritori de cuvinte pare a avea radacini adinci si este fara indoiala autoimpusa, un factor important ce a contribuit la perpetuarea ei fiind teama de a nu cadea in ridicol. Exista in ceea ce ii priveste pe multi români o anumita "pudoare" legata de limbaj, care ii impiedica sa construiasca ei insisi cuvinte noi pentru ca se tem ca acestea ar putea declansa accese de ilaritate din partea celor care le-ar auzi pentru prima data. Insa inovatia, indiferent de domeniul de aplicare, se bazeaza in buna parte pe curajul unor persoane de a incerca ceva nou, chiar daca rezultatele nu vor fi de la inceput pe masura asteptarilor si chiar daca initial incercarea va stirni hohote de ris. Una din caracteristicile care ii deosebesc pe creatorii de succes de aceia care se opresc la jumatatea drumului este hotarirea cu care isi continua munca, chiar si in conditii de adversitate. Creatorilor care stiu ca sint pe drumul cel bun le este indiferenta parerea celorlalti, pentru ca sint siguri ca ei vor avea dreptate in cele din urma si nu aceia care le contesta sau le iau in deridere activitatea. Depasirea sentimentului de ridicol care insoteste orice initiativa de a crea un cuvint nou este deci prima etapa care trebuie parcursa de cineva care isi propune sa participe la imbogatirea limbii române in calitate de creator, nu de importator sau de colportor. Insa frica de a nu cumva fi etichetat drept un nou propovaduitor al izolarii lingvistice fata de limbile de mare circulatie internationala este de ajuns pentru a-i face sa renunte pe cei mai multi dintre aceia care ar dori sa propuna un cuvint nou. O acuza si mai de efect care li se aduce frecvent celor care au curajul sa sustina ca importul nesabuit de neologisme ar trebui stopat este aceea ca vor sa intoarca România pe vremea "gîtlegăului", iar limitarea importului de neologisme ar avea ca efect inapoierea culturala si stiintifica a tarii. Cuvintul "gîtlegău" nu a intrat niciodata in uzul comun, dar a fost unul dintre protagonistii principali ai unei dispute care a avut loc in secolul 19 intre sustinatorii înnoirii limbii române prin import de neologisme si cei care sustineau crearea unor cuvinte noi dintr-unele deja existente. Gîtlegăul era propunerea acestora din urma pentru obiectul de imbracaminte care este cunoscut azi sub numele de cravata. Acest cuvint a fost creat prin fuziunea cuvintelor gît si legătura, cu o usoara modificare a acestuia din urma din motive gramaticale, pentru ca rezultatul sa aiba 3 silabe (gîtlegău) si nu 5 (gîtlegătura), astfel fiind mai usor de pronuntat. Prin comparatie, cuvintul "cravata" vine de la denumirea poporului care a purtat prima oara acest obiect, in limba croata "Hrvatska" insemnind "Croatia". Pentru că panglica de material textil purtata la git de mercenarii croati din Franta a devenit in scurt timp foarte populara, cuvintul "hrvatska" a suferit citeva modificari si a ajuns la forma "cravate", in asa fel incit sa poata fi usor pronuntat de catre francezi, care sint cunoscuti pentru accentul pus pe eleganta imbracamintii, ei adoptind foarte repede inventia croatilor. In limba româna "cravata" a patruns deci prin intermediul limbii franceze. Daca este sa judecam exclusiv dupa criteriul estetic, cuvintul "cravata" este mai melodios si sugereaza cumva faptul ca avem de-a face cu un articol de lux, asa cum era in acele timpuri. Dar daca este sa judecam dupa criteriul utilitatii cuvintului, dupa cit de usor se intelege despre ce este vorba, atunci "gîtlegău" ar fi mai potrivit, pentru ca nimeni nu ar dori sa spuna ca poarta o "croată" la git. Decizia de a folosi "cravata" in loc de "gîtlegău" nu mai poate fi rasturnata acum si nici nu ar fi de dorit acest lucru, dar trebuie subliniat faptul ca ea a avut citeva consecinte extrem de nefaste asupra limbii române. In momentul transarii disputei dintre importatorii si creatorii de cuvinte in favoarea primilor, tabara creatorilor a suferit nu numai o infringere zdrobitoare, ci a fost condamnata la blamare vesnica pentru vina inchipuita de a impiedica modernizarea limbii, iar cuvintul "gîtlegău" a primit un loc in "infernul" cuvintelor si isi petrece penitenta arzînd neincetat la flacara dispretului general. Consecinta cea mai grava a disputei dintre importatori si creatori a fost insa abandonarea completa a creării de cuvinte noi prin fuzionarea unora deja existente in favoarea importului de neologisme. Acest lucru se poate vedea cel mai bine in ziua de azi, cind pentru cuvintele englezesti aparute masiv in limbajul de zi cu zi nu exista nici un rival creat prin fuzionarea unor cuvinte autohtone. Singurele cuvinte românesti care par compuse prin fuziune sint in fapt tot neologisme, deci fuziunea a avut loc in limbile de origine, dar ramine aparenta si in româna. Ceea ce este insa extrem de ironic in toata povestea legata de "gîtlegău", este ca acest cuvint si-a pierdut dreptul de a exista in limba româna, dar si l-a obtinut in limba engleza, in special cea vorbita in USA. Prin intermediul acesteia el a intrat si in vorbirea unor români, care ar fi dealtfel oripilati daca li s-ar cere sa renunte la cuvintul "cravata" in favoarea "gîtlegăului". Ei bine, in dialectul nord-american al limbii engleze (cel vorbit in USA) cuvintul folosit pentru panglica purtata in jurul gitului este "necktie", care este evident format prin fuzionarea cuvintelor "neck" ("git") si "tie" ("legatura"). Iata ca usamericanilor nu le este rusine sa spuna ca poarta un "gitlegau" in loc de o cravata si nu isi pun problema ca limba vorbita de ei este una retrograda, invechita. Trebuie dealtfel mentionat ca in engleza vorbita in Marea Britanie se foloseste in special cuvintul "tie" pentru "cravata", desi exista si cuvintul "cravat" (provenit din franceza), care este insa mult mai putin folosit. Este deci de remarcat toleranta vorbitorilor nativi de limba engleza, care au la dispozitie mai multe variante pentru "cravata" (necktie, tie, cravat, neckcloth) si le accepta pe toate, fara sa faca crize de isterie sau sa se lanseze in acuzatii ridicole. Desi popoarele englez si român au fost despartite de o distanta geografica foarte mare, limba engleza are unele similitudini de evolutie istorica cu limba româna. Astfel, atit limba engleza cit si cea româna isi au punctul de plecare in limba vorbita de "cotropitorii" unui teritoriu, fiind deci vorba de limbi neautohtone teritoriului in care s-au definitivat. In cazul englezei invadatorii au fost triburile de origine germanica (angli, saxoni, etc.) care au ocupat un teritoriu locuit de triburi celtice, a caror limba avea o identitate proprie, pastrata si in ziua de azi in principal sub forma limbii irlandeze. La fel ca si in cazul românei, limba vorbita initial in insula Marea Britanie (care cuprinde Anglia, Tara Galilor si Scotia) a disparut complet, fiind inlocuita de limba noilor-veniti, care a fost pina la urma acceptata si de autohtoni. O a doua etapa in formarea limbii engleze a fost cucerirea normanda, care a facut ca limba oficiala in Marea Britanie sa devina pentru o suta si ceva de ani limba franceza, mai precis un dialect vechi al ei, vorbit de normanzi. Aceasta perioada a facut ca in limba engleza sa isi faca loc multe cuvinte de origine franceza, care se intilnesc si azi si nu sint socotite neologisme. Masivul aport de cuvinte frantuzesti in limba engleza se asemana cu influxul la fel de mare de cuvinte de origine slava in limba româna, efectul in ambele cazuri fiind unul de imbogatire lexicala, foarte benefic pentru niste limbi aflate in formare, care aveau nevoie urgenta de cuvinte pe baza carora sa se dezvolte limba literara. Limba literara este limbajul folosit in operele cu caracter cultural-stiintific si reprezinta intruchiparea cea mai elevata a unei limbi. Ea are drept caracteristici principale claritatea in exprimare, bogatia lexicala si corectitudinea gramaticala. Limba literara este in primul rind un factor unificator, pentru ca ea aduce la un numitor comun diversele dialecte regionale ale unei limbi. In al doilea rind, limba literara este un factor de stabilitate, pentru ca nu permite remodelarea regulilor gramaticale decit in anumite limite si asta doar daca este neaparata nevoie. In al treilea rind, limba literara este un factor de progres, ea fiind aceea care decide imbogatirea vocabularului cu cuvinte si expresii noi, legitimind sau nu uzul acestora. Limba engleza este de origine germanica si are in comun cu limba germana moderna usurinta de a crea cuvinte noi prin fuziunea unora deja existente. Englezii sint un popor cu un simt al practicului foarte dezvoltat si acest lucru se vede si in modul in care si-au alcatuit vocabularul. Ori de cite ori au avut nevoie de un cuvint nu au stat mult pe ginduri si l-au creat rapid prin procedeul fuziunii, fara sa le pese ca noul cuvint ar putea declansa zimbete pentru ca ar fi prea "rustic", fiind lipsit de vreun semn de "noblete" estetica, asa cum par a avea cuvintele moderne care au radacini grecesti sau latine. Aceasta metoda de imbogatirii a limbii a dat rezultate foarte bune pentru ca nu s-a mai pierdut timp cu adoptarea de cuvinte straine, dintre care unele nu se puteau adapta cerintelor gramaticale ale limbii engleze. Pe de alta parte cuvintul rezultat prin fuziune avea de multe ori un sens atit de evident, incit toata populatia (indiferent de gradul de educatie) putea sa-si dea seama usor la ce se referea cuvintul respectiv, spre deosebire de cuvintele create pe baza unor teme (radacini) grecesti sau latine, al caror inteles ar fi trebuit explicat in prealabil. Vocabularul englez are deci la baza in primul rind criteriul functional (utilitar) si nu pe cel estetic, iar acest lucru a permis adaptarea rapida a limbii la cerintele societatii moderne. Mai mult, in limba engleza coexista pasnic cuvinte create prin fuziune cu unele importate, iar acest lucru nu deranjeaza pe nimeni. In cazul limbii române lucrurile stau cu totul diferit, in primul rind din cauza absentei cuvintelor create prin fuziune, care lasa loc liber importului de cuvinte pentru imbogatirea vocabularului. Insa desi neologismele sint utile pentru orice limba, afluxul lor masiv pune in pericol integritatea limbii importatoare, lasind la o parte faptul ca multe dintre ele nu vor fi intelese prea usor de majoritatea populatiei. Spre deosebire de anglo-saxoni (englezi, usamericani, etc.) care vad cuvintele prin prisma functionalitatii lor, românii au tendinta sa receptioneze in principal aspectul estetic al cuvintelor, si cu cit acestea sint mai melodioase, mai placute la auz, cu atit ele sint mai des folosite. O parte din români par a avea in ultima vreme timpanul extrem de "sensibil", si numai auzul unor cuvinte care se termina cu grupurile de litere "oi" sau "ău", considerate specifice cuvintelor "neaoşe", pare a le produce o "inflamatie" suparatoare a urechii, care aparent se transmite si la creier si le determina reactii de "greata" lingvistica. Bineinteles ca de cele mai multe ori "inflamatia" nu apare la auzul unor cuvinte englezesti care si ele se termina in "oi", dovada ca totul se reduce la un dispret abia mascat fata de limba româna si o admiratie nemarginita fata de cea engleza. O astfel de situatie s-a petrecut atunci cind eu am propus inlocuirea englezismului "flame-war" cu un cuvint inventat de mine si anume "flamboi", rezultat prin fuziunea cuvintelor "flamă" si "război". Foarte multi internauti care au intervenit pe firul de discutie dedicat disputelor aprinse de pe forumuri au reactionat violent sau batjocoritor, displacindu-le sonoritatea "taraneasca" a termenului inventat de mine, uitind bineinteles de numarul mare de cuvinte englezesti care se termina in "oy" (pronuntat"oi"), printre care si celebrul "cowboy", aflat la mare pret printre usamericani si admiratorii acestora. Ca o ironie a soartei, in acelasi an in care avea loc discutia la care am facut referinta isi incepea cariera stralucita un cuvint englezesc nou-inventat si el, anume "fanboi" (pronuntat "fenboi"), care desemneaza persoanele cu o admiratie "fanatica" fata de produsele unei anumite companii. Acest cuvint este din ce in ce mai raspindit pe forumurile de discutii, iar sonoritatea sa nu i-a impiedicat in nici un fel adoptarea de catre vorbitorii de limba engleza, dovada ca acestia pun pret mai mare pe capacitatea de semnificare a cuvintului decit pe sonoritatea lui. Se pare deci ca in cazul limbii române trebuie depasite mai intii niste piedici psihologice, care ii mentin pe români in conditia de cîrpaci cu cuvinte straine si îi impiedica sa redevina creatori ai propriei lor limbi. Poate ca exemplul limbii engleze unde complexele psihologice de inferioritate aplicate cuvintelor nu isi au locul, ar trebui luat in seama. Ar trebui de asemenea descoperita placerea inventiei de cuvinte noi, care este la latitudinea fiecarui vorbitor de limba româna. La fel ca orice proces de creatie si acela prin care se plamadesc cuvinte poate sa nu fie incununat de succes de la inceput. Dar perseverenta si rafinarea metodelor folosite pot duce la rezultate foarte bune. Inventarea unui cuvint care are ulterior priza la public si incepe sa fie folosit de cit mai multi oameni are ca rezultat intarirea increderii in potentialul creativ al propriei persoane. Aceasta recompensa este bineinteles de ordin spiritual, dar cresterea increderii in fortele proprii poate duce ulterior si la recompense pe plan material, atunci cind alte si alte proiecte creative vor fi duse la bun sfirsit. Descoperirea potentialului creator al unei persoane poate deci incepe cu o actiune aparent banala, cum ar fi crearea unui cuvint de care este nevoie la un moment dat. |
|
Cuvintele adoptate din limbi straine se
numesc
neologisme si au un rol extrem de util, anume acela de a suplini
lipsa unor
termeni autohtoni pentru descrierea anumitor notiuni (obiecte,
actiuni, etc.). Avem
deci de-a face cu un proces care implica o limba exportatoare (limba
straina) si una importatoare (limba autohtona, in cazul nostru
româna). Cum
orice limba este suportul unei culturi, se poate apecia fara a gresi
prea
mult ca in procesul de adoptare a neologismelor un rol determinant
il are
echilibrul de forte intre cele doua culturi participante, in sensul
ca
intotdeauna cultura mai "slaba" va importa (cuvinte, dar si idei)
din
cultura mai "puternica". In cazul României influentele diferitelor
culturi
puternice si-au pus amprenta de-a lungul timpului asupra
vocabularului, prin
influxuri uneori masive de neologisme. Trebuie mentionat ca sint
socotite
neologisme doar cuvintele adoptate dupa ce procesul de formare a
limbii a
fost definitivat, astfel ca de exemplu cuvintele provenite din
slavona (rusa
veche), existente intr-un procent de 30% in vocabularul românesc, nu
intra
in categoria neologismelor pentru ca ele au participat la formarea
limbii si
sint parte integranta din ea de foarte multa vreme. Nimeni nu ar
putea
socoti de exemplu ca familia de cuvinte ce exprima cel mai bine
sentimentul
dragostei (iubire, a iubi, iubit, etc.) ar fi compusa din
neologisme, pe
motivul ca la baza ei stau cuvinte de origine rusa (liubov, liubiti,
etc.).
Adoptarea neologismelor in
limba româna a fost favorizata in secolul 19 si prima jumatate a
secolului
20 de principalele influente culturale europene care si-au pus
amprenta
asupra culturii române, in speta culturile franceza si germana.
Sfirsitul
secolului 20 si inceputul secolului 21 stau sub influenta
covirsitoare a
culturii de origine anglo-saxona, in special cea din Statele Unite
ale
Americii (USA). Influenta pe care o are aceasta tara in majoritatea
domeniilor de activitate umana (incepind de la stiinta si terminind
cu
politica) este de netagaduit si probabil nu are corespondent in
istoria
umanitatii. Hegemonia culturala usamericana se bazeaza pe activitatea intelectualilor din USA care isi fac publice eforturile prin canalele de distributie a lucrarilor stiintifice sau culturale si din ce in ce mai mult si prin publicare pe internet. Este deci vorba de prezentarea unor teze (idei), si nu de impunerea lor cu forta. Faptul ca din ce in ce mai multi oameni din toate partile lumii considera produsele culturale usamericane ca fiind cele mai bune la ora actuala este un lucru de inteles si nu poate fi privit ca fiind ceva rau in sine. Insa adoptarea in mod necritic a culturii usamericane are si un efect pervers, anume acela de a induce un complex de inferioritate in rindul oamenilor care traiesc in tari mai mici, a caror cultura nu poate rivaliza cu cea usamericana, din motive variate (populatie mai mica, fonduri pentru cultura foarte reduse, etc.). Din pacate cetatenii (si chiar guvernele) unor astfel de tari incearca iesirea din starea neplacuta provocata de complexul de inferioritate nu prin tratarea cauzelor acestuia (lipsa de productivitate a culturii locale), ci prin negarea lui, ceea ce are ca efect cresterea dependentei fata de cultura usamericana. Edificiile intelectuale (operele stiintifice si culturale) sint produse ale gindirii umane, iar forma lor concreta este realizata cu ajutorul limbajului scris. Un aspect particular al acestora este faptul ca receptarea adecvata a sensului lor de catre o anumita persoana este dependenta de gradul de intelegere de catre persoana in cauza a limbajului in care au fost concepute. Cu alte cuvinte, daca o lucrare a fost scrisa in limba engleza, atunci intelegerea ei presupune de obicei invatarea limbii engleze. Bariera limbajului poate fi depasita si daca avem acces la o traducere a lucrarii intr-o limba pe care deja o cunoastem, cea materna sau alta. Ritmul accelerat de publicare a lucrarilor stiintifice si culturale face insa ca varianta traducerii sa fie din ce in ce mai putin probabila, pentru ca traducerea necesita un efort de munca important care este destul de scump. Produsele de divertisment audo-vizual (filme si muzica) in limba engleza sint probabil principalele responsabile pentru promovarea limbii engleze si a culturii usamericane la nivel mondial. Raspindirea folosirii calculatoarelor si a internetului a contribuit si ea la hegemonia limbii engleze, din motive ce tin de softurile folosite si de materialele existente pe internet. Nu exista o statistica precisa a numarului de opere cultural-stiintifice publicate anual, insa o estimare aproximativa ar releva probabil faptul ca aproape jumatate din acestea sint elaborate sau traduse in limba engleza. Invatarea limbii engleze a devenit de voie - de nevoie o disciplina obligatorie in sistemul de invatatamint din majoritatea tarilor globului, tocmai pentru ca societatile respective sa poata sa mentina contactul cu stiinta si cultura moderna. Cel mai palpabil efect al dominatiei culturii usamericane asupra celorlalte culturi de pe glob este importul masiv de catre acestea din urma a unor cuvinte din limba engleza. In masura in care aceste neologisme au suplinit lipsa unor cuvinte autohtone si in acelasi timp s-au adaptat regulilor gramaticale ale limbilor importatoare, procesul poate fi privit ca fiind unul benefic. Insa orice proces care se desfasoara rapid si cu o intensitate mare nu poate fi controlat corespunzator si ca urmare isi fac aparitia efectele nocive. Suvoiul de neologisme de origine engleza care se revarsa in toate limbile aparent nu mai poate fi stapinit si tinde sa elimine din aceste limbi unele cuvinte autohtone, la fel cum un torent de apa dezradacineaza arborii intilniti in cale. Situatia limbii române in momentul de fata este destul de critica, desi exista voci care spun ca ea va rezista, asa cum a facut-o si pina acum in fata altor limbi din care au fost preluate multe cuvinte, de exemplu franceza. Insa situatia din secolul 19 nu se poate compara cu cea din secolul 21. In secolul 19 cei care impuneau modificarile limbii literare erau lingvistii si scriitorii profesionisti (romancieri, poeti, jurnalisti, etc.), deci un numar relativ mic de oameni raportat la totalul populatiei. Au existat bineinteles si excese, cum a fost de exemplu dorinta unor scriitori (sau chiar lingvisti) de eliminare completa a cuvintelor de origine slava si inlocuirea lor cu neologisme provenite din limbile franceza sau italiana. Astfel de manifestari arbitrare si irationale au avut un impact minor, tocmai pentru ca majoritatea intelectualilor nu le-au sprijinit. Per total se poate spune ca limba româna a intrat in secolul al 20-lea mai bogata si mai moderna, pastrindu-si insa toate caracteristicile ei de baza. Lucrurile stau insa diferit acum, la inceputul secolului al 21-lea, cind toata populatia stie sa scrie, iar o mare parte din ea o si face, in principal pe internet, care a devenit in ultimul timp platforma preferata pentru expunerea parerilor proprii. Marirea numarului de "scriitori" nu s-a insotit insa si de o crestere a respectului acestora fata de limba româna, care este unealta ce ii ajuta sa isi exprime ideile. Limbajul scris folosit pe internet de catre majoritatea românilor are caracteristica de a fi înţesat cu cuvinte si sintagme englezesti mai mult sau mai putin adecvate, in locul unora românesti care ar putea exprima perfect opiniile autorului. Cuvintul dintr-o limba straina care este folosit in locul unui cuvint autohton, desi ambele au acelasi inteles, se numeste "barbarism". Denumirea are o nuanta peiorativa, aceasta fiind o mostenire a termenului folosit de cele doua mari civilizatii europene antice (greaca si romană) pentru a desemna persoanele care nu le apartineau. Un termen mai potrivit pentru cuvintele neautohtone ar fi "străinisme", care nu mai induce nuanta peiorativa, fiind deja incetatenita folosirea unor termeni care indica originea cuvintelor straine, de exemplu "englezisme", "frantuzisme", etc. Dar "barbarism" sugereaza cel mai bine comportamentul unui cuvint strain care nu se pliaza regulilor limbii in care este introdus, la fel cum "barbarii" de odinioara nu doreau sa respecte normele sociale ale marilor civilizatii antice. Marele pericol al acceptarii "barbarismelor" in limba româna este potentialul lor distructiv asupra structurii de baza a limbii. Ceea ce diferentiaza barbarismele de neologismele "civilizate" este tocmai faptul ca nu se pot incadra in regulile gramaticale existente, pentru ele trebuind sa fie adoptate exceptii de la aceste reguli. Dar cu cit se accepta mai multe exceptii de la o regula gramaticala, cu atit regula respectiva devine mai insignifianta si intr-un sfirsit va fi desfiintata. Gramatica este schela pe care este cladit "edificiul" limbii, iar dezagregarea unei portiuni din aceasta schela poate avea consecinte dezastruoase pentru intregul edificiu. Persoanele care folosesc barbarisme in limbajul curent nu sint constiente probabil ca in acest fel incurajeaza introducerea unor "cai troieni" in limba româna, care in timp pot sa o distruga. La fel ca si un organism viu, limba unui popor a evoluat lent si a ajuns la o stare de echilibru. Barbarismele nu fac decit sa atace permanent acest echilibru, iar numarul lor in continua crestere le va usura mult sarcina. Cei care vor avea de suferit de pe urma acestui deznodamint vor fi tocmai cei care au contribuit la el, dar nu i-au prevazut consecintele sau nu le-a pasat de ele. Insa poate ca barbare nu sint cuvintele, ci chiar oamenii care pentru a se simti "la moda", distrug (in mod inconstient sau cu buna stiinta) o limba cladita pe parcursul a sute de ani. Exista in momentul de fata din ce in ce mai multe persoane de toate virstele care se "remarca" prin folosirea barbarismelor, in special pe internet, dar din ce in ce mai frecvent si in limbajul de zi cu zi. Iar cei care indraznesc sa le atraga atentia asupra limbii "stricate" pe care o folosesc sint luati in ris sau insultati. Folosirea barbarismelor nu este nici pe departe un semn de cultura sau de modernitate, din contra este cel mai bun indiciu al superficialitatii in gindire si al respingerii unui minim efort intelectual care ar implica folosirea cuvintelor românesti, mult mai adecvate pentru a comunica si a face inteles orice tip de mesaj. Pentru persoanele care folosesc cu precadere barbarisme in limbajul curent (scris sau vorbit) voi folosi de acum incolo denumirea de "barbarişti". Chiar si in lipsa ajutorului oferit de catre cei care o vorbesc, limba româna are citeva mecanisme de aparare intrinseci, care ii permit sa nu accepte atit de usor neologisme. Trebuie mentionat ca indiferent de cit de multi oameni folosesc un anumit cuvint strain, acesta nu va putea niciodata sa acceada la statutul de neologism daca nu reuseste sa se adapteze particularitatilor gramaticale ale limbii române. Pentru ca un cuvint strain sa poata fi acceptat ca neologism ar trebui sa fie respectate urmatoarele criterii :
Din pacate, persoanele care folosesc englezisme in ziua de azi nu isi mai pun problema sa le adapteze la caracterul fonetic al limbii române, ci se asteapta ca un cuvint englezesc sa isi pastreze atit forma lexicala cit si pronuntia originara. Domeniul informaticii ne ofera nenumarate exemple in acest sens: englezescul "driver" este scris ca atare in româna, dar este pronuntat "draiver" si nu "driver", cum ar fi fost corect. Alte exemple sugestive de neadaptare sint barbarismele care contin litere duble (de ex, oo sau cc). In limbile straine grupurile de vocale cum sint "oo" sint pronuntate diferit fata de literele constituente. De exemplu in cazul englezismului [to] "boot", pronuntia originara este "but". Cei doi de "o" sint folositi in acest caz pentru ca daca s-ar fi folosit un "u", cuvintul s-ar fi pronuntat in engleza "băt". In limba româna varianta corecta a acestui neologism trebui deci sa fie "a buta" si nu "a boota". Un alt cuvint scris gresit de unii internauti este "spammer". In limba engleza cei doi de "m" sint necesari pentru a se obtine pronuntia "spamăr". Daca s-ar folosi un singur "m", pronuntia in engleza ar fi "speimăr". Limba româna nu foloseste consoane duble decit foarte rar, iar in acest caz nu are nevoie de al doilea "m" pentru a pastra o pronuntie aproape de cea originara, deci el trebuie sa dispara. Atunci cind se are in vedere adoptarea unui neologism, trebuie sa se tina cont si de usurinta cu care va putea fi el folosit in limbajul vorbit. Unele limbi straine, ca de exemplu engleza, au cuvinte care contin grupuri de consoane, dar acest lucru nu altereaza pronuntia originara prea mult pentru ca unele din acestea nu sint in fapt rostite. De exemplu in limba engleza cuvintul "thread" se pronunta "tred", consoana "h" fiind aproape ignorata in pronuntie. Multi internauti români folosesc insa pe forumurile de discutii barbarismul "thread" in locul cuvintului românesc "fir", care are practic acelasi inteles. Cum "thread" se pronunta in româna asa cum se scrie, asta ar insemna ca multora sa li se contorsioneze limba in gura atunci cind l-ar rosti. Dar fiind vorba de o comunicare scrisa, pronuntia lui "thread" nu ii deranjeaza pe forumistii români. Daca insa ar trebui sa comunice oral, ei ar renunta imediat la el si ar folosi românescul "fir", care il traduce perfect pe "thread" si este extrem de usor de pronuntat. Una dintre cele mai importante particularitati ale limbii române se refera la modul de articulare a cuvintelor. Articolul hotarit este partea de vorbire care ne permite sa semnalam ca in discursul nostru ne referim in mod specific la un anumit obiect, care le este cunoscut interlocutorilor nostri. In majoritatea limbilor straine articolul hotarit se pune inaintea cuvintului pe care il determina (de ex. "the core", cuvint englezesc). Insa in limba româna articolul hotarit se ataseaza sub forma de sufix (se "sudeaza") la portiunea terminala a cuvintului articulat. Daca luam ca exemplu cuvintul "nucleu", atunci forma articulata hotarit a acestuia este "nucleul", unde l-ul terminal este tocmai articolul hotarit, care asa cum se vede este alipit la radacina cuvintului articulat. Cele mai multe barbarisme nu trec "testul" articolului hotarit, adica este imposibil sa le atasezi una din formele de articol hotarit din limba româna, fara a reiesi o monstruozitate lexicala. De exemplu englezismul "core" (pronuntat "cor") este folosit de multi internauti in loc de românescul "nucleu", desi ambele cuvinte au acelasi inteles. Ei bine, "core" nu va putea deveni niciodata un neologism acceptat pentru ca el nu se poate articula corect. Forma articulata hotarit "coreul" este inacceptabila pentru ca vocalele e si u formeaza un diftong, iar vocala e ar trebui sa dispara, daca nu cumva se accepta pronuntia "coreul". Insa daca ea ar dispare s-ar pastra pronuntia corecta din engleza, dar ar apare confuzia intre noul cuvint si unul deja existent, "cor", care semnifica un grup de persoane care cinta impreuna. Solutia este binenteles renuntarea la barbarism si folosirea cuvintului "nucleu". O alta practica paguboasa a utilizatorilor de barbarisme este formarea pluralului acestora pornind de la forma la singular, la care adauga unul din sufixele specifice pluralului in limba română, separat cu o cratimă (liniuţa " - ") de restul cuvintului. Forma rezultata este grotesca, dar evident ca pentru persoanele nefamiliarizate cu gramatica română acest lucru nu conteaza. De exemplu cuvintul englezesc "controller" este folosit in exact aceasta forma de multi internauti, iar cind vine vorba de fomarea plurarului ei scriu "controller-e". In limba româna pluralul nu se face cu ajutorul cratimei, deci aceasta varianta nu va fi niciodata acceptata in limba literara. Eventual, englezescul "controller" va putea intra in româna doar in forma "controler" (fara "l" dublu), iar pluralul va fi "controlere". Un alt exemplu chiar mai sugestiv este cel al cuvintului englezesc "layer" (plural "layers"), care se traduce in limba româna prin "strat". Ei bine, multi utilizatori ai programelor de editare grafica folosesc barbarismul "layer", caruia i-au realizat si un plural românesc cu adevarat barbar si anume "layer-e". In acest fel ar trebui sa existe doi termeni in limba româna cu acelasi inteles, dintre care unul ("strat") sa fie folosit exclusiv in situatiile care nu privesc informatica, iar celalalt ("layer") sa intre in functiune cind fraza care il contine are legatura cu informatica. Ridicolul acestei situatii este perceput de orice om cu bun-simt lingvistic. Trebuie inteles de catre barbarişti ca folosirea cratimei nu este "machiajul" care permite mascarea unui barbarism in asa fel incit acesta sa intre linistit in limba română. Englezismele care nu se vor adapta perfect limbii române (inclusiv prin abandonarea cratimei in formarea pluralului sau in cazul articularii hotarite) nu vor fi acceptate in vocabularul limbii literare. Respectarea regulilor limbii române este deci esentiala pentru ca un neologism sa se integreze perfect in ea si sa fie acceptat ca un cuvint cu "drepturi egale" cu ale celorlalte deja existente. Chiar daca un numar mare de oameni folosesc zilnic un barbarism, asta nu inseamna ca el va putea fi vreodata acceptat in limba literara daca nu se pliaza regulilor limbii române. Gramatica este o stiinta, iar cei mai in masura sa se pronunte asupra ei sint specialistii, adica lingvistii. Nici un lingvist român de valoare nu va accepta vreodata ca sa fie afectat caracterul fonetic al limbii române sau ca sa fie introduse neologisme care se pot declina doar cu ajutorul cratimei. Limbajul scris practicat pe multe din forumurile românesti este deci fundamental gresit si nu va putea fi legitimat niciodata din punctul de vedere al gramaticii române. Cei care continua sa foloseasca barbarisme isi fac rau lor însişi, pentru ca vor uita sa scrie corect in limba româna, iar modul lor "stricat" de a scrie nu va fi acceptat niciodata in limba literara. Consecintele pentru ei se vor vedea mai tirziu, atunci cind vor avea de redactat un material oficial. Acesta va trebui scris conform cu normele gramaticale in vigoare, iar ei vor avea dificultati in a-l concepe si vor trebui in ultima instanta sa suporte consecintele dezinteresului manifestat fata de folosirea corecta a limbii lor materne. |
|
Influxul de neologisme care a avut loc
incepind
cu anul 1990 a fost fara indoiala cel mai important din toata
istoria limbii
române. Fiecare domeniu de activitate si-a imbogatit jargonul
specific cu
cel putin citeva zeci de cuvinte provenind din limba engleza. Marea
majoritate a lor sint insa barbarisme care au corespondenti in limba
româna,
dar acestia din urma sint mai putin folositi din motive mai degraba
care tin
de psihologia individului sau a grupului decit de lingvistica.
Daca este sa singularizam un
singur domeniu care este campion la importul de barbarisme acela
este cel
legat de tehnologia informatiei. Informatica este o disciplina
relativ noua
ale carei baze au fost puse in USA in urma cu citeva zeci de ani. La
fel ca
in cazul oricarei discipline stiintifice a fost nevoie de alcatuirea
unui
jargon specific, cuprinzind termenii necesari pentru a desemna
precis
notiuni legate strict de domeniul nou-aparut. Insa daca pina atunci
termenii
stiintifici erau creati in special pe baza unor cuvinte grecesti sau
latine, tocmai
pentru a li se conferi un caracter de universalitate, in cazul
informaticii
s-a renuntat la aceasta procedura si s-au folosit de la inceput
termeni
preluati din limba engleza obisnuita, cea vorbita in viata de zi cu
zi.
Trebuie deci subliniat inca o data spiritul practic al
usamericanilor care
au luat din vocabularul limbii engleze niste cuvinte existente deja
si le-au
(re)folosit pentru notiunile pe care doreau sa le denumeasca. De
exemplu
atunci cind a trebuit sa fie denumit un dispozitiv care permitea
interactionarea mai usoara cu calculatorul i s-a dat numele de
"mouse",
pentru ca firul de conectare cu calculatorul facea ca dispozitivul
sa semene
cu un soarece. Lumea s-a obisnuit foarte usor cu acest nume si
nimanui nu i
s-a parut ridicol. Procedura de numire a unor notiuni din domeniul
informaticii folosind cuvinte comune a continuat pina in ziua de
azi, fara
ca sa declanseze accese de ilaritate din partea nimanui.
O mare parte din termenii informatici sint deci cuvinte folosite de sute de ani in limba engleza, evident cu alte intelesuri decit cele specifice calculatoarelor. Insa sensul principal a ramas cel folosit in limbajul obisnuit. Atunci cind cautam cuvintul "mouse" in dictionarul Merriam-Webster (referinta suprema in domeniul dictionarelor explicative englezesti), prima definitie este intotdeauna cea privitoare la micul mamifer binecunoscut. Dispozitivul de interactionare cu calculatorul apare de-abia pe locul patru. Deci un englez care rosteste cuvintul "mouse" se poate referi fie la rozator (cel mai frecvent), fie la dispozitivul de indicare, in functie de contextul discursului sau. Atunci cind el intra intr-un magazin de calculatoare si ii spune vinzatorului ca doreste sa cumpere un "mouse", vinzatorul nu izbucneste intr-un ris incontrolabil, pentru ca este evident ca se refera la dispozitiv si nu la rozatorul viu, desi ambele au aceeasi denumire. Aceasta concordanta intre cuvintele obisnuite si termenii informatici nu este inteleasa de unii utilizatori români ai calculatoarelor, care sustin preluarea in bloc a tuturor termenilor informatici englezesti, chiar daca acestia au in principal un caracter non-tehnic ("mouse", "thread", "core", etc.). In viziunea "barbaristilor" ("utilizatorilor de barbarisme") traducerea termenilor englezesti in limba româna ar fi aproape o blasfemie si ar duce la o stare de ilaritate (veselie) generala. Motivatia introducerii termenilor englezesti nu sta in picioare pentru ca avem de-a face cu aplicarea unui dublu standard, adica folosirea unor "unitati de masura" diferite aplicate la niste situatii asemanatoare. Pe de o parte, un român ar trebui sa se simta prost daca s-ar duce la un magazin de calculatoare din Bucuresti si ar spune ca vrea sa cumpere un "soarece", dar pe de alta parte acest lucru nu se aplica pentru un usamerican care ar cere sa cumpere un "mouse" dintr-un magazin localizat in New-York. Care sa fie explicatia pentru standardul dublu de judecare a unor circumstante identice? Sint vinzatorii români mai neseriosi decit cei usamericani si izbucnesc in ris din orice? Este cuvintul românesc "soarece" o traducere nepotrivita pentru cuvintul englezesc "mouse"? Nu, nici una din aceste doua ipoteze nu este cea care ne-ar permite intelegerea motivatiei barbaristilor. Si asta pentru ca nu se ia in considerare factorul psihologic introdus de barbaristi in ecuatie. Ceea ce nu le convine lor este apropierea jargonului informatic de limbajul obisnuit, pentru ca marea lor majoritate se mindresc cu faptul ca stiu sa foloseasca calculatorul, lucru socotit de ei ca fiind un semn de elevare intelectuala, care ii situeaza deasupra unei bune parti a populatiei. In momentul in care ei ar trebui sa vorbeasca despre folosirea calculatorului folosind cuvinte românesti "banale", aura lor de "invatati" s-ar diminua, pentru ca orice "profan" si-ar da seama ca utilizarea calculatorului nu este cel mai greu lucru de pe pamint, ci din contra unul din cele mai simple, odata ce sint deprinse citeva notiuni de baza. Cuvintul "mouse" este doar virful aisbergului de barbarisme care pluteste pe "apele" limbii române, iar "vizibilitatea" sa (faptul ca este foarte folosit) l-a facut protagonistul principal al eforturilor barbaristilor de a-l "adapta" cît de cît limbii române, in conditiile pastrarii nealterate a formei sale originare. In limba engleza cuvintul "mouse" nu respecta regula formarii pluralului, el avind un plural neregulat si anume "mice". Ei bine, pluralul le-a dat mari batai de cap barbaristilor români, care au dat la iveala forme pe cit de ridicole, pe atit de distractive. Una din ele este "mouse-i" (pronuntata mauşi"), cu varianta "mousei" (pronuntata la fel, dar cu sufixul pluralului sudat la cuvint). Cautarea pluralului perfect pentru "mouse" continua si in prezent pe forumurile românesti, desi cu un efort minim cei interesati ar fi putut descoperi ca in Dictionarul Explicativ al Limbii Române (editia 1998) exista deja cuvintul "maus" (plural "mausuri") care desemneaza tocmai dispozitivul de interactionare cu calculatorul. Lingvistii care au redactat DEX au inventat cuvintul "maus" si l-au folosit in locul traducerii "soarece", pentru ca astfel să împace "capra" gramaticii române (noul cuvint este perfect adaptat acesteia) cu "varza" multora din utilizatorii români, care s-ar fi simtit jigniti sa spuna ca pun mina pe un "soarece" atunci cind lucreaza la calculator, spre deosebire de utilizatorii englezi care nu considera ca fac un lucru injositor cind folosesc "soarecele" pentru a da comenzi calculatorului. Desi varianta "maus" propusa in DEX este foarte buna si merita sa ramina forma finala a cuvintului in limba româna, ea este respinsa de barbaristii din "aripa dura", hotariti sa nu renunte cu una cu doua la englezismul "mouse". O metoda asemanatoare de inventare a unui cuvint nou a fost folosita si de mine atunci cind am creat cuvintul "hardisc", in locul englezismului "hard disk". Exemplele de cuvinte englezesti non-tehnice folosite de barbaristii români in locul corespondentelor lor românesti sint nenumarate. Absolut orice cuvint englezesc, indiferent cit de banal, este ridicat la rangul de termen din domeniul informaticii, iar termenul românesc corespondent este ignorat cu desavirsire, desi de cele mai multe ori este mai usor de scris si de pronuntat. Oricine arunca o privire pe forumurile românesti vede ca in cadrul discutiilor este folosit cuvintul englezesc "link" in locul celui autohton "legătură", corespondentul sau perfect. Desi barbarismului "link" i s-a inventat un plural ("link-uri") care nu suna deloc bine in limbajul vorbit, el este totusi preferat de multi cuvintului corect ("legături"), pentru ca "rusinea" de a folosi un cuvint a carui pronuntie poate fi asociata cu denumirea populara a unei părti a anatomiei umane ("cur") este mai mica decit aceea de a folosi un cuvint socotit prea banal pentru moderna si interesanta stiinta a informaticii. Nici macar grotescul cuvintelor derivate din "link" ("a link-a", "link-eaza", "link-at", etc.) nu ii face pe barbaristi sa le tremure mina cind scriu, ei nedorind in ruptul capului sa utilizeze cuvintele românesti corecte ("a lega", "leagă", "legat", etc.). La fel sta situatia si in cazul cuvintului englezesc "shortcut", apartinind limbajului obisnuit, care se traduce prin "scurtătură". In cele mai multe texte scrise in româna si disponibile pe internet este folosit barbarismul "shortcut", in locul cuvintului românesc cu acelasi inteles. Englezii folosesc termenul "shortcut" in principal atunci cind spun "to take a shortcut" ("a o lua pe scurtătură"), referindu-se bineinteles la folosirea unei rute mai scurte pentru a ajunge la destinatie. Tot englezii folosesc "shortcut" si atunci cind spun "to create a shortcut to a file" ("a crea o scurtătură catre un fisier"), referindu-se la realizarea unei cai de acces rapid la un fisier. Cele doua intelesuri ale termenului "shortcut" nu intra in conflict unul cu celalt si in functie de context se deduce intelesul adecvat. Acest mod de comportament normal nu este pe placul barbaristilor români, care ar dori ca atunci cind este vorba de un text referitor la informatica sa se foloseasca exclusiv englezismul "shortcut", iar in restul cazurilor sa poata fi folosit "invechitul" scurtatura. Sau poate ca le place atit de mult englezismul incit ei il folosesc si cind merg cu masina zicind ca "o iau pe shortcut" ? Tot in lumea forumurilor românesti isi face veacul si barbarismul "nickname", adoptat cu bratele deschise de internautii români, care nu ar folosi românescul "poreclă" pentru nimic in lume, desi are acelasi inteles si in plus este mai scurt si mai usor de scris decit corespondentul sau englezesc. Discutarea fiecarui barbarism in parte ar fi interesanta din punct de vedere al analizei psihologice care ar incerca sa descopere resortul ascuns al adoptarii lui in locul cuvintului românesc similar. De ce se foloseste "thread" in loc de "fir" ? Cuvintul "thread" este folosit de sute de ani de catre croitoresele engleze cu intelesul de "aţă" si are sensul mai general de "fir". Nu este deci vorba de un termen tehnic nou aparut, ci de unul transferat din limbajul obisnuit in jargonul informatic pentru a desemna înşiruirea unor mesaje publicate pe un forum de discutii. Nu exista nici o motivatie rationala pentru a nu folosi românescul "fir" in loc de "thread", mai ales ca acesta din urma este mai greu de scris si de pronuntat. La fel, de ce se folosesc verbele imposibile d.p.d.v. gramatical "a share-ui" (pronuntat "a şărui"), " a host-a" (sau a "host-ui"), "a boot-a", in loc de variantele românesti corecte "a partaja", "a gazdui" sau "a buta" ? Cu ce este mai bun englezismul "click" fata de corespondentul sau românesc "clic", prezent chiar si in DEX? Descifrarea resortului care sta in spatele preferintei barbaristilor români pentru englezisme neadaptate limbii române (greu de scris si de pronuntat), poate fi realizata doar prin apelarea la ipoteze cu iz psihologic. Una din ele este evidentă, si anume admiratia fara limite in fata limbii engleze, care este socotita superioara limbii române, desi lucrurile stau in realitate tocmai invers. Folosirea unui simulacru de limba engleza îi face poate pe unii internauti sa se simta mai puternici, pentru ca in subconstientul lor se simt mai apropiati de civilizatia usamericana, din care si-ar dori sa faca parte cit mai repede. Exista in cazul românilor o dorinta latenta de a se lasa cuceriti, inclusiv la nivel lingvistic, de catre natiunile mai puternice? Se spera că prin grefarea nefericita de englezisme in româna se poate crea impresia apartenentei la civilizatia anglo-saxona ? Este cumva "îngenuncherea" limbii române in fata celei engleze semnalul unui servilism lingvistic, care desăvîrşeşte opera "politicii in genunchi" exhibata cu nonşalanţă in ultimii ani de guvernantii români fata de cei usamericani ? Nimic nu ilustreaza mai bine prosternarea unora din români in fata limbii engleze decit barbarismul "site" (pronuntat "sait"), folosit de multi in locul cuvintului românesc corect "sit" (pronuntat asa cum se scrie). Cei care folosesc varianta "site" (plural "site-uri" - pronuntat "saituri") si o apăra cu inversunare dovedesc ca nu cunosc etimologia acestui cuvint. El provine din limba latina, unde "situs" inseamna in principal "aşezare" ("loc"). Din limba latina cuvintul a trecut in limba franceza, dar sub o forma usor modificata si anume "site" (pronuntat "sit"), pastrindu-se deci o pronuntie aproape de cea originara. In sfirsit, englezii au preluat cuvintul frantuzesc "site" si i-au pastrat forma, dar evident ca rezultatul a fost schimbarea pronuntiei, care a devenit "sait". Cuvintul a circulat deci pe traseul latina-franceza-engleza cu modificari ale formei sau ale pronuntiei, dar asta nu il poate face sa fie privit ca un cuvint englezesc pur, el raminind un cuvint latin modernizat la trecerea prin limba franceza si importat ulterior in limba engleza. Cum limba româna este de origine latina, rezulta ca forma "sit" este cea care trebuie folosita, nu varianta modificata ("site") existenta in limba engleza. Ar fi de un ridicol desavirsit ca limba româna sa primeasca un cuvint latin, nu din limba de origine (cu care se inrudeste direct), ci prin intermediul unei limbi nelatine. Dar varianta "site" nu are numai "pacatul" ca nu provine direct de la sursa, ci si pe acela ca nu se adapteaza limbii române. Conform caracterului fonetic al acesteia, cuvintul "site" ar trebui sa fie citit asa cum se scrie si s-ar crea confuzia cu pluralul cuvintului care desemneaza ustensila de bucatarie cunoscuta ca "sită". Si bineinteles ca formarea pluralului unui cuvint românesc cu ajutorul cratimei ("site-uri") este incorecta d.p.d.v. gramatical. Limba româna face parte din grupul limbilor neolatine alaturi de italiana, franceza, spaniola si portugheza. Pentru a desemna o locatie pe internet in italiana exista termenul "sito" (pronuntat "sito"), in franceza "site" (pronuntat "sit"), iar in spaniola si portugheza "sitio" (pronuntat "sitio"). Din motivele expuse mai sus, in limba româna trebuie folosit termenul corect derivat din latina si anume "sit". In concluzie, introducerea de cuvinte din jargonul informatic de limba engleza in limba româna trebuie sa se faca in general doar pentru termenii strict tehnici, iar forma neologismelor rezultate trebuie sa fie adaptata gramaticii limbii române si sa respecte caracterul fonetic al acesteia. De exemplu dispozitivul denumit "router" in limba engleza trebuie sa fie denumit in limba româna "ruter". O situatie particulara se intilneste in cazul cuvintului englezesc "chip" (pronuntat "cip"). La origine acesta este un termen non-tehnic, ce poate fi tradus in româna prin cuvintul "aşchie". El a fost preluat din limbajul obsnuit in jargonul informatic pentru că redă foarte sugestiv aspectul procesoarelor, care sint niste "aşchii" (placuţe) de siliciu pe care sint gravate microcircuite electronice. Traducerea termenului "chip" poate parea foarte simpla, pentru ca termenul englezesc nu ar avea probleme sa se integreze d.p.d.v. gramatical in limba româna. Insa daca el ar fi importat in forma originara s-ar crea o confuzie cu termenul "chip" ("faţă") care exista deja in româna si este foarte folosit. De aceea varianta ideala pentru traducere este cuvintul "cip", care seamana bine cu originalul englezesc si este adaptat si limbii române. In mod similar cuvintul "chipset" se traduce prin "cipset". Traducerea termenilor informatici englezesti care provin din cuvinte uzuale (non-tehnice) este primul pas catre aducerea informaticii mai aproape de utilizatorii români, in special cei incepatori. O buna parte a populatiei românesti percepe utilizarea calculatorului ca pe un lucru greu de inteles si asta pentru ca se confrunta de la bun inceput cu doua handicapuri, cel al lipsei cunostintelor in acest domeniu si cel al neintelegerii termenilor englezesti, care trebuie invatati pe dinafara. Traducerea termenilor non-tehnici i-ar ajuta foarte mult pe incepatorii români si i-ar pune pe picior de egalitate cu cei din USA sau Anglia, care nu au in fata decit bariera cunostintelor, nu si pe cea a unui limbaj complet strain. Timpul cistigat in acest fel le-ar permite incepatorilor români sa aprofundeze sensul termenilor tehnici, cei care trebuie cu adevarat intelesi pentru a avansa in descoperirea lumii calculatoarelor. |
|
Foarte multe domenii tehnologice au fost influentate masiv de
avansul
tehnologiilor digitale din ultimii ani, printre ele fiind de exemplu
fotografia. Aparatele foto au devenit din ce in ce mai mult niste
minicalculatoare la care singurul efort depus de om este apasarea
butonului
de declansare a captarii imaginii dorite. Faptul ca toate reglajele
pot fi
facute automat a facut ca utilizarea aparatelor foto sa fie la
indemina
oricui, aproape indiferent de virsta sau de pregatire. Asta nu
inseamna ca
toti cei care fac fotografii se transforma automat in fotografi
profesionisti, dar faptul ca ei practica fotografia le permite sa
doreasca
sa abordeze subiecte din acest domeniu sau pur si simplu sa
comenteze
impreuna cu altii gradul de îndemînare la care au ajuns. O mare
parte din
fotografii amatori au dorinta de a invata mai mult si de aceea se
indreapta
catre sursele de informare pe care le au la indemina. Exista
bineinteles
carti de specialitate in limba romana dar ele sint percepute ca
fiind foarte
scumpe, desi de cele mai multe ori continutul lor le justifica
pretul. Si
atunci cei mai multi dintre fotografii amatori se indreapta catre
internet,
unde informatiile sint abundente si mai ales gratuite, insa de multe
ori
calitatea lor nu se apropie de cea din cartile tiparite. Ei bine, pe cit de folositor este internetul prin multitudinea de informatii care sint puse la dispozitie gratuit, pe atit este el de "nociv" din cauza faptului ca marea majoritate a acestor informatii exista intr-o singura limba, cea engleza. Practic asistam nu numai la extinderea unei "monoculturi" (cea anglo-saxona) la nivel mondial, dar si la dominatia covirsitoare a limbii engleze, care tinde sa isi impuna vocabularul de termeni in toate domeniile activitatii umane, de multe ori fara a tine cont de existenta unor termeni autohtoni similari ca sens, care au deja o vechime apreciabila. Ramine sa ne punem intrebarea ce este de facut in aceasta situatie pentru a salva culturile sau limbile nationale, atit de vulnerabile in fata tavalugului cultural-stiintific de limba engleza. Metoda cea mai la indemina in ceea ce priveste internetul este sa crestem numarul de materiale originale care sint scrise in limba pe care nu dorim sa o lasam sa dispara sau sa se transforme intr-o limba vasala celei engleze. Eventual se poate apela si la traduceri ale materialelor scrise in original in engleza, dar in aceasta situatie trebuie bineinteles obtinut acordul autorilor. Insa internetul nu contine numai informatie fixata in articole, ci si informatie oferita prin intermediul forumurilor sau listelor de discutii. In viata reala limba vorbita (folosita pentru comunicare directa) influenteaza in cele din urma limba literara, acest lucru fiind valabil si pentru lumea virtuala a internetului, unde limba folosita pe forumuri tinde sa se impuna ca "limba oficiala" a internautilor, in special in ceea ce priveste terminologia folosita in domeniile pe marginea carora se discuta (calculatoare, fotografie, muzica, etc.). Spre deosebire de limba folosita in articole sau carti, cea folosita pe forumuri nu pune aproape nici un pret pe modul de prezentare a informatiilor, accentul fiind pus exclusiv pe continut. Deci este perfect acceptabil in vizunea majoritatii forumistilor ca un mesaj care contine o cantitate de informatie utila sa poata fi deficitar la capitolul exprimarii corecte d.p.d.v. gramatical, stilistic sau lexical. Aceasta atitudine tolerantă a fost propice pentru aparitia unui limbaj propriu forumurilor romanesti care este înţesat cu barbarisme provenite din engleza. De exemplu in domeniul fotografiei au ajuns sa se foloseasca englezismele "viewfinder" si "lightmeter" in loc de termenii romanesti consacrati de multa vreme, anume "vizor" si "exponometru". Situatia este complicata de cele mai multe ori de faptul ca englezismul este folosit ca atare sub forma sa din limba engleza, fara a se incerca o adaptare la cerintele gramaticale ale limbii romane. Pur si simplu se ia un cuvint englez (substantiv, verb, etc.) care este apoi este cirpit dupa nevoie cu sufixe (terminatii) legate cu cratima in functie de modul in care trebuie folosit (plural, articulare, conjugare, etc.). Inca si mai grav este faptul ca aceste sufixe sint inventate "dupa urechea" forumistului si astfel se ajunge ca un anumit englezism sa faca flexiunea in mod diferit dupa persoana care il foloseste. Un exemplu este barbarismul derivat din verbul englez "to host" ("a gazdui") care apare atit in forma " a host-a" cit si in cea de "a host-ui", care face prezentul la persoana intii ca "eu host-ez" sau "eu host-uiesc". A incerca sa se schimbe mentalitatea referitoare la utilizarea corecta a limbii romane de catre forumisti este probabil una din cele mai grele incercari care sta in fata celor preocupati de destinul limbii romane. Si asta pentru ca forumurile sint niste comunitati care si-au creat in timp anumite reguli nescrise, una fiind cea legata de limbajul folosit. Iar cine incearca sa ocoleasca aceste reguli va fi mai devreme sau mai tirziu admonestat daca nu se pliaza regulilor si eventual fortat sa se retraga din comunitate. De exemplu a vorbi pe un forum romanesc despre "fir de discutie" si nu despre "thread" inseamna a te expune ridicolului public, desi cuvintul "thread" este un barbarism care nu are ce cauta in romana, nefiind un termen tehnic ci unul banal care se traduce perfect prin "fir". Exemplele pot continua, cert este ca limbajul vorbit pe forumuri are tendinta de a se auto-intretine si de a se degrada din ce in ce mai mult, pe masura ce apar internauti din generatiile mai tinere, pentru care limba romana nu a reprezentat niciodata o preocupare. Persoanele responsabile cu mentinerea ordinii pe forumuri (proprietari, administratori si moderatori) nu descurajeaza in mod explicit folosirea unui limbaj incorect de catre forumisti, tocmai pentru ca acest lucru ar duce la scaderea numarului de participanti la discutii, deci a numarului de vizitatori, in functie de care se incaseaza venituri din publicitate. Asta nu inseamna ca situatia forumurilor este disperata, doar ca va trebui depus un efort de convingere a persoanelor cu functii de raspundere in asa fel incit acestea sa inteleaga necesitatea emiterii daca nu a unor norme, cel putin a unor recomandari (sustinute cu exemple) referitoare la folosirea corecta a limbii romane. In societatea actuala este foarte mult apeciata fluiditatea informatiilor, noutatea lor si din aceasta cauza atit internetul cit si revistele au un avantaj fata de carti, de aici rezultind si influenta lor mai mare asupra celor care cauta sa isi imbogateasca bagajul informational într-un anumit domeniu. Revistele apar de obicei lunar si evident ca ofera un continut mult mai proaspat (dar nu neparat mai bun) decit cartile, pentru care pot fi scoase editii noi cel mult odata la citiva ani. Rezulta ca numarul celor care folosesc revistele ca mijloc de informare sau de perfectionare este mai mare decit al celor care folosesc cartile. Ca urmare limbajul scris folosit in reviste tinde sa se impuna in fata celui folosit in carti, ceea ce nu este deloc un lucru bun din perspectiva limbii romane. Redactorii care scriu la reviste nu se vad decit eventual in postura de profesionisti ai domeniului despre care scriu, nu si in cea de profesionisti ai limbii romane, asa cum ar trebui sa fie cazul. O persoana care utilizeaza zi de zi in scris limba romana pentru a-si asigura existenta ar trebui sa devina interesata cu timpul de pastrarea in stare cit mai buna a "uneltei" care ii permite sa supravietuiasca. Acest lucru nu se intimpla insa din motive diverse, unul fiind acela al nevoii unei productivitati crescute, care se combina cu anumit grad de delasare intelectuala si de nepasare pentru starea limbii romane. Redactorul care trebuie sa scrie citeva articole pentru numarul lunar al revistei se documenteaza de obicei pe internet si in mod inevitabil marea majoritate a materialelor pe care le foloseste ca referinte sint scrise in limba engleza. Fie ca este presat de timp, fie ca nu, redactorul nostru nu va cauta de cele mai multe ori sa vada daca nu cumva unii din termenii straini (englezesti de obicei) pe care el ii include in articol au deja corespondenti in limba romana al caror uz este deja incetatenit de multa vreme in rindul specialistilor. Se ajunge astfel ca publicul cititor sa devina familiarizat mai degraba cu termenul englezesc pentru un anumit element (actiune, dispozitiv, etc.) decit cu cel romanesc, care este uneori aflat in folosinta specialistilor de citeva zeci de ani. Un barbarism preferat de multi redactori este "layer", folosit pentru a desemna unul din straturile care compun o imagine digitala. Sonoritatea muzicala a acestui termen a avut probabil un rol important in adoptarea lui, insa nimeni nu ia in seama constructiile grotesti care trebuie facute in cazul in care cuvintul este acceptat, de exemplu "layer-izat" in loc de "stratificat". Conducerea revistelor trebuie sa inteleaga faptul ca are o responsabilitate fata de limba romana si ca urmare trebuie sa puna la punct o politica editoriala care sa implice folosirea de catre redactori a unui limbi romane in care barbarismele sa nu-si mai gaseasca locul. Situatia actuala a limbii romane ar trebui sa ingrijoreze multa lume, de la simplii cetateni pina la profesionistii scrisului, specialistii in lingvistica si chiar autoritatile publice. Doar prin combinarea eforturilor acestor categorii de oameni se poate stopa declinul limbii romane si restabilirea prestigiului ei. O prima masura ar putea fi realizarea unui dictionar de traducere a termenilor tehnico-stiintifici din engleza in romana, care sa fie publicat pe internet, in asa fel incit el sa poata fi consultat gratuit de oricine doreste sa scrie corect articole in romana, indiferent daca o face pentru situl propriu sau in cadrul obligatiilor de servici. Dar acest dictionar nu pot fi opera unei singure persoane, ci el trebuie sa fie un efort colectiv realizat prin conlucrarea dintre persoane cu pregatire de specialitate in domenii variate si a unor filologi, de exemplu in cadrul unui proiect colaborativ de tip WIKI. Se va putea astfel pune la dispozitia internautilor un dictionar englez-roman care sa cuprinda termeni din informatica, medicina, chimie, inginerie, etc. O alta masura ar putea fi impunerea de catre autoritatile de stat din domeniul culturii ca fiecare magazin care vinde componente de calculator sa aiba obligatoriu in oferta si tastaturi cu semnele diacritice specifice limbii romane. Nu trebuie uitat ca gindirea noastra s-a nascut si traieste in interiorul limbii romane, deci cu cit pastram limba mai curata si mai conforma cu esenta sa originara, cu atit gindirea va putea sa se dezvolte mai bine si sa fructifice potentialul de creativitate existent in fiecare din noi. |
|
Secolul 21 se doreste a fi unul al ratiunii, in care sa primeze
intelegerea
intre persoane apartinind unor culturi diferite, in asa fel incit
razboaiele
care au marcat atit de puternic secolul 20 sa nu se mai produca.
Necesitatea
existentei unei limbi universale este cu atit mai stringenta cu cit
datorita
internetului lumea se transforma pe zi ce trece intr-o uriasa
comunitate la
nivel planetar, in care piedicile cele mai mari in calea comunicarii
intre oameni nu mai sint de ordin fizic (spatial), ci cultural. O
limba universala,
care sa poata fi invatata usor de toata lumea, este deci solutia
care ar permite
atenuarea diferentelor de ordin cultural prin intelegerea si
acceptarea
acestora. Dar tocmai pentru ca traim intr-un secol in care
tehnologia capata o
importanta din ce in ce mai mare, o limba universala va trebui in
acelasi
timp sa poata fi
intrebuintata cu usurinta nu numai in comunicatiile interumane, ci
si in
cele dintre oameni si masini. Limba romana este cea mai indicata
pentru a deveni limba universala datorita
caracteristicilor sale intrinseci, care o fac foarte usor de invatat
si de
utilizat atit de catre oameni cit si de catre masini. Desi aceasta
afirmatie
poate parea ca izvorind din convingeri de tip nationalist, la baza
ei stau
exclusiv argumente de ordin pragmatic.
Cel mai convingator
argument in sprijinul superioritatii limbii romane fata de orice alt
limba
vorbita pe glob este caracterul ei fonetic aproape perfect, care se
traduce
prin corespondenta nemijlocita intre semn (litera) si sunetul
semnificat de
acesta. In limba romana o litera se pronunta intotdeauna in acelasi
fel,
indiferent de locul ei in cadrul cuvintului. A se compara acest
lucru cu
limba engleza, unde o aceeasi litera se pronunta diferit in functie
de locul
precis ocupat in cuvint. De exemplu litera "A" din cuvintul
englezesc "can"
se pronunta de fapt "e", litera "a" din cuvintul "able" se pronunta
"ei",
litera "a" din cuvintul "car" se pronunta "a", iar litera "a" din
cuvintul
"motherboard" nu se pronunta deloc. Alt exemplu sugestiv este litera
"E"
care in cuvintul englezesc "secret" se pronunta "i", in timp ce in
cuvintul
"pen" se pronunta "e". Dar nu numai vocalele prezinta diferenţe
importante
de pronuntie in engleza, ci si consoanele. Litera "S" se pronunta
"s" in
cuvintul "sea", insa se pronunta "ş" in "sure" sau "z" in "desert".
O alta particularitate a limbii engleze care o face dificil de
invatat este si faptul ca unele cuvinte care sint scrise identic se
pronunta
diferit. De exemplu cuvintul "live" poate fi folosit ca adjectiv si
atunci
se pronunta "laiv" ("live broadcasting" - "transmisiune directă"),
sau
poate fi folosit ca verb ("a trăi") si atunci se pronunta "liv"
("they live
here" - "ei trăiesc aici") O persoana care invata limba romana nu trebuie decit sa auda un anumit cuvint si va sti sa il scrie imediat. In limba engleza acest lucru nu este suficient, trebuie ca pentru fiecare cuvint sa fie invatat si modul in care se scrie acesta, tocmai pentru ca exista cuvinte care se pronunta la fel dar se scriu in mod diferit. Oricine a vizitat forumurile de pe internet in limba engleza a vazut ca insisi vorbitorii nativi ai acestei limbi au dificultati in a scrie corect unele cuvinte, care sint de altfel foarte des folosite. Una din cele mai raspindite greseli de scriere este cea a cuvintului "than" ("decît"), care este frecvent scris "then" ("atunci"), pentru ca desi semnifica lucruri complet diferite, ambele cuvinte se pronunta exact la fel. Alta greseala des intilnita pe forumurile englezesti este scrierea cuvintului "separate" ca "seperate", in acest caz pronuntia fiind aceeasi, insa al doilea cuvint neexistind de fapt in dictionar. Dificultatea scrierii corecte in limba engleza face ca de multe ori pe forumuri sa apara scris dupa unele cuvinte "(sp?)", ceea ce indica faptul ca autorul mesajului (de cele mai multe ori avind engleza ca limba materna) nu este sigur de modul in care se scrie corect cuvintul respectiv. In fapt ortografia (scrierea corecta - "spelling") este o disciplina atit de importanta pentru limba engleza, incit existind concursuri scolare chiar de nivelul olimpiadelor pentru testarea cunostintelor si asta nu numai la clasele mici. Pentru vorbitorii de limba romana astfel de concursuri nu isi au rostul, neexistind o diferenta intre literele care se aud la pronuntia unui cuvint si cele din care este el scris. Înşişi vorbitorii nativi de engleza si-ar dori ca engleza sa fie o limba fonetica precum romana, tocmai pentru ca le-ar usura mult exprimarea si i-ar scapa pentru totdeauna de cosmarul corectitudinii ortografice care îi bîntuie de fiecare data cind scriu ceva. Este adevarat ca exista softuri speciale de verificare a ortografiei engleze, insa ele nu sint intotdeauna la indemina sau nu este timp pentru rularea lor. Tocmai din cauza asta unii usamericani (in special tinerii), incearca sa impuna pe internet folosirea unor variante scrise al cuvintelor englezesti care sa respecte criteriul fonetic si nu pe cel ortografic. Astfel cuvintul "cause" este uneori scris "cuz", "was" este scris "wuz", "says" este scris "sez", etc.. Iata deci ca in timp ce romanii incearca sa "anglicizeze" limba romana pentru a o face mai "interesanta", prin importul masiv de neologisme englezesti nedaptate gramaticii romane, usamericanii incearca sa "românizeze" limba engleza pentru a o face mai practica, dorind sa o transforme intr-o limba fonetica, lucru contrar regulilor gramaticale engleze. Limba romana are o particularitate care îi consolideaza si mai mult caracterul fonetic, anume prezenta diacriticelor. Aceste semne se adauga unor litere latine (a, i, s, t) pentru a semnala o modificare a pronuntiei lor. In acest fel romana poate sa mentina relatia "o litera - un sunet" si pentru sunete pentru care nu exista literele corespondente in alfabetul latin. In timp ce engleza foloseste grupuri de doua litere pentru aceste sunete ("eh", "uh", "sh", "tz"), limba romana foloseste cite o singura litera (ă, î, ş, ţ) pentru fiecare sunet. Desi diacriticele le par unora ca fiind o caracteristica arhaica sau un semn al înrudirii românei cu unele limbi balcanice (turca in special), ele reprezinta de fapt o adaptare a alfabetului latin la specificul limbii române, o limba moderna care a evoluat odata cu poporul ce o vorbeste, in timp ce evolutia latinei s-a incheiat demult. Faptul ca româna foloseste o singura litera (modificata cu ajutorul diacriticelor) in loc de un grup de doua litere intareste si comparatia dintre limba si un organism viu, pentru ca asa cum se stie toate organismele vii incearca sa atinga un grad cit mai mare de eficienta energetica, adica sa realizeze o actiune cu un consum energetic cit mai mici. Diacriticele vin mai ales in sprijinul scriitorilor permitindu-le sa isi reduca efortul fizic (prin scrierea unei litere in loc de doua) si astfel sa isi conserve resursele energetice, care devin astfel disponibile pentru un travaliu de durata mai lunga. Atunci cind se discuta despre caracterul fonetic al limbii romane nu trebuie omise modificarile ortografice recomandate de Academia Romana (AR) in anul 1993, care induc o exceptie in ceea ce priveste regula "un sunet - o litera" existenta in limba romana. Astfel prevederea ca "sunetul î sa se redea in scris prin literele â si î in functie de pozitia lor in cuvint" este de o absurditate nemarginita, venind sa submineze punctul forte al limbii romane si anume caracterul ei fonetic perfect. Motivatia care a stat la baza recomandarii a fost de ordin sentimental si nu stiintific. S-a spus ca folosirea in exclusivitate a literei î mascheaza originea latina a unor cuvinte romanesti si astfel poate fi pusa la indoiala originea latina a limbii romane. Insa simplul fapt ca de exemplu cuvintul "cîine" nu seamana prea bine cu cuvintul latinesc "canis" din care este derivat nu duce automat la concluzia ca romana nu este o limba latina. Caracterul latin al limbii romane este demonstrat in principal de structura ei gramaticala si abia apoi de multele cuvinte romanesti care semana mult cu omoloagele lor latine. Pe de alta parte conform recomandarilor AR cuvintul "rîu" ar trebui scris "râu", iar acest lucru nu face decit sa-i ascunda originea latina (cuvintul "rivus"), lucru valabil si pentru "fân", cuvint provenit din latinescul "fenum". Exista multe alte situatii care demonstreaza ca folosirea lui â in loc de î este contrara etimologiei (originii) cuvintului. Un alt efect nefast al modificarii ortografice din 1993 este faptul ca pentru anumite cuvinte forma lor scrisa trebuie invatata pe de rost. De exemplu cuvintul "reîntîlnire" ar trebui scris "reîntâlnire", dar multi vor aplica automat noua regula impusa de AR (sunetul "î" din interiorul cuvintului sa fie scris "â") si il vor scrie gresit "reântâlnire". Se vede deci ca modificarile ortografice recomandate de AR nu fac decit sa creeze confuzie in mintea vorbitorilor de romana si sa ingreuneze procesul de invatare si scriere a limbii de catre romani sau straini. In concluzie motivatia AR pentru folosirea a doua semne (î si â) pentru acelasi sunet nu sta in picioare, pentru ca nu este coerenta cu ea insasi. Cealalta recomandare a AR ("prezentul indicativ al verbului a fi sa fie scris si pronuntat : sunt, suntem, sunteti in loc de sînt, sîntem, sînteti") este un nou exemplu de sentimentalism adus la rangul de stiinta. Varianta "sînt" s-a impus de foarte multa vreme prin folosirea de zi cu zi a limbii, tocmai pentru ca este mai usor de pronuntat decit "sunt" si permite o cursivitate mai mare a exprimarii vorbite. Modificarile ortografice recomandate de AR in 1993 nu au nici o baza stiintifica sau rationala, iar pentru binele limbii romane prezente si viitoare, ele nu trebuie folosite. Una din promisiunile inca neimplinite ale erei informaticii este comunicarea directa prin voce intre om si masina. Desi s-au facut eforturi mari in acest sens, iar tehnologia actuala permite oricarui calculator aparut relativ recent sa ruleze softuri de recunoastere vocala ("voice recognition") sau de citire de text ("text-to-speech"), rezultatele sint departe de asteptari si asta tocmai pentru ca aceste softuri au fost concepute pentru limba engleza. Masinile au nevoie ca datele care le sint furnizate ("input") sa fie foarte clare pentru ca prin prelucrarea lor sa fie produse rezultate corecte ("output"). Ele nu au flexibilitatea creierului uman care invata sa lucreze foarte usor cu exceptiile de la regulile gramaticale, alegind varianta corecta in functie de context. Citirea textelor in limba engleza de catre calculatoare a dus in cele din urma la rezultate multumitoare, dar asta numai dupa un efort foarte mare din partea programatorilor, care au trebuit sa ia in calcul toate particularitatile de exprimare vocala a limbii engleze ce decurg din lipsa de corespondenta intre cuvintul scris si cel vorbit. Succesul relativ obtinut se datoreaza insa si faptului ca datele pe care le prelucreaza calculatorul nu sint variabile, adica avem de-a face cu un text scris, iar calculatorul trebuie doar sa recunoasca literele care compun un cuvint si apoi sa il rosteasca, de-abia aceasta a doua etapa fiind mai dificila, pentru ca asa cum am spus mai sus pronuntia unei litere difera in functie de pozitia ei in cadrul cuvintului. In cazul recunoasterii vocale progresele facute nu sint atit de importante, pentru ca aici intervine factorul uman cu variabilitatea sa intrinseca. Fiecare om are o voce unică, nemaîntilnita la altcineva, care este caracterizata de amplitudine, timbru si tonalitate. Pe linga aceste caracteristici care tin mai mult de conformatia anatomica, fiecare om are si un anume fel unic de a vorbi, caracterizat de viteza cu care vorbeste, de inflexiunile vocii si de dicţie (claritatea pronuntiei). Toate aceste particularitati pot produce dificultati de comunicare chiar si intre oameni, pentru ca nu este usor sa intelegi ce spune cineva care vorbeste prea repede sau pronunta cuvintele in mod neclar, insa urechea si creierul uman reprezinta un tandem mult mai bine adaptat la receptarea vocii si interpretarea continutului ei decit tandemul "microfon - soft de recunoastere vocala". A pune la punct un program care sa interpreteze corect cuvintele in limba engleza spuse de mai multi oameni este un lucru care s-a dovedit foarte greu, iar rezultatele sint pe masura, adica neconcludente. Fiecare soft de recunoastere vocala (de ex. cel inclus in MS Office 2003, bazat pe motorul de recunoastere vocala produs de Microsoft) are nevoie de o antrenare prealabila pentru o anumita voce, tocmai pentru ca sa poata lua in calcul caracteristicile sonore ale vocii respective atunci cind trebuie sa interpreteze continutul mesajului vorbit. Chiar si asa rezultatele sint de multe ori nesatisfacatoare, existind chiar si situatii in care diferenta dintre cuvintul rostit de om si cel "ghicit" de calculator da nastere la situatii ilare (rizibile). Softul poate fi folosit cu rezultate ceva mai bune atunci cind este vorba de unele comenzi simple, insa dictarea unui text pune numeroase probleme, tocmai din cauza faptului ca limba engleza il pune in dificultate pe calculator in situatiile neclare, de exemplu atunci cind trebuie sa aleaga din mai multe cuvinte care se pronunta la fel, cuvintul care se potriveste sensului textului dictat. Daca mai adaugam si faptul ca majoritatea oamenilor care nu sint vorbitori nativi de engleza au probleme in a pronunta cuvintele englezesti respectind intonatia si accentul corect, atunci este de inteles de ce softurile de recunoastere vocala nu sint foarte folosite in momentul de fata. Unele din dificultatile pe care trebuie sa le surmonteze calculatorul in sarcina sa de a vocaliza corect limba engleza scrisa sint prezentate intr-un articol de pe situl Societatii Americane de Lingvistica. Argumentele din articol pot fi verificate cu orice soft de tipul text-in-voce ("text-to-speech"). Utilizarea limbii romane pentru comunicarea cu calculatorul ar face mult mai usoara interactiunea dintre om si masina. Dat fiind caracterul fonetic al limbii romane, citirea unui text de catre calculator nu ar intimpina nici o dificultate din partea acestuia, pentru fiecare litera existind un singur sunet care trebuie memorat de catre softul calculatorului. Chiar si in ceea ce priveste recunoasterea vocala lucrurile ar fi mult mai simple in cazul folosirii limbii romane, pentru ca "auzind" un anumit cuvint romanesc calculatorul poate sa deceleze foarte usor literele din care este format acesta si apoi sa-l identifice cu mare precizie, nemaiexistind incertitudinile determinate de cuvintele care se rostesc la fel dar se scriu in mod diferit, asa cum se intimpla in cazul limbii engleze. Tinind cont de toate argumentele in sprijinul superioritatii intrinseci a limbii romane fata de limba engleza care au fost prezentate mai sus, este cel putin stranie atitudinea multor romani care isi considera limba materna ca fiind o limba de categoria a doua, inferioara celei engleze. Admiratia fara limite fata de limba engleza este probabil datorata necunoasterii caracteristicilor lingvistice ale acestei limbi. Oricine viziteaza forumurile romanesti este uimit de numarul mare de cuvinte englezesti din mesajele internautilor, ca si cum romanilor le-ar fi rusine sa-si vorbeasca propria limba si ori de cite ori au posibilitatea folosesc cuvinte englezesti in locul celor romanesti. Insa o privire mai atenta asupra continutului mesajelor postate pe forumuri arata ca de fapt "fanii" neinduplecati ai limbi engleze nu sint niciodata cunoscatori in profunzime ai acestei limbi, ci poseda doar o cunoastere de suprafata, care se limiteaza la cititul si scrisul unor cuvinte frecvent folosite, uneori fara a le intelege pe deplin sensul lexical. Cea mai mare parte dintre ei nu stiu sa se exprime coerent in scris in limba engleza, dovada fiind numeroasele greseli de exprimare atunci cind incearca sa scrie o fraza, nu numai cuvinte disparate. O alta dovada a superficialitatii cunoasterii englezei de catre cei mai mari "fani" ai ei este faptul ca sectiunile in limba engleza ale forumurilor romanesti (acolo unde ele exista) sint pustii, tocmai pentru ca aici s-ar vedea clar gradul redus de stapinire a limbii engleze de catre majoritatea internautilor si nimeni nu doreste sa-si expuna ignoranta in vazul tuturor. Reiese clar de aici ca "fanii" limbii englezei o dispretuiesc in interiorul lor la fel de mult ca si pe limba romana, din moment ce nu isi dau silinta de a o invata in mod corespunzator, lucru care nu ar necesita un efort prea mare. Cheia scrierii corecte in engleza este inainte de toate scrierea corecta in romana, pentru ca aceia care scriu gresit in romana vor face la fel si in engleza, deoarece ei nu inteleg necesitatea respectarii regulilor gramaticale proprii fiecarei limbi. Internautii anglofoni refuza sa gindeasca pe termen lung si nu isi dau seama ca ei vor fi primii care se vor plinge de abundenta cuvintelor englezesti in romana. Si asta pentru ca ei cunosc bine doar cuvintele din jargonul informatic, dar in momentul in care vor apare in limbajul uzual multe englezisme din alte domenii (medicina, economie, industrie, arta, etc.) nu vor putea sa le invete pe toate si se vor face de ris atunci cind nu le vor intelege sensul si pe desupra le vor scrie gresit. Cei care stau mult pe internet invata cum se scrie "site" pentru ca il intilnesc frecvent, insa asta nu inseamna ca le va conveni atunci cind vor trebui sa invete cum se scriu termeni folositi in jargonul economic de limbă engleza, precum "supply", "income" sau "expenditure", daca aceste cuvinte vor incepe sa fie folosite in textele romanesti in detrimentul corespondentelor autohtone ("oferta", "venit", "cheltuiala"). De fapt aceste lucruri se intimpla si acum, de exemplu in cazul cuvintului "poll" ("sondaj de opinie"), folosit frecvent pe forumuri, care de multe ori este scris gresit de internauti sub forma "pool", cuvint cu un sens ("baltă") complet diferit fata de cel intentionat. O alta greseala frecvent intilnita pe forumuri este considerarea unor cuvinte romanesti care exista in vocabular de multa vreme ca fiind importuri recente din engleza. In acest sens exista multi internauti (daca nu chiar majoritatea) care cred ca "forum" a patruns in limba romana doar de citiva ani, odata cu aparitia forumurilor online de pe internet, cind in fapt el exista in romana de mai bine de un secol. Pluralul lui "forum" nu este deci scris "forumuri" asa cum ar fi corect, ci este scris "forum-uri", dupa regula inventata de internautii anglofoni, conform careia un englezism face pluralul din forma sa la singular la care se aduga terminatia "uri" despartita de cuvint printr-o cratima. Dependenta de cratima pentru articularea si formarea plurarlului ii face pe internautii anglofoni sa faca tot felul de greseli ortografice ("text-ul", "regulament-ul", "avatar-ul"), in toate aceste cazuri formele corecte fiind scrise fara cratima, pentru ca este vorba de cuvinte deja existente in romana de multa vreme. Din cauza potentialului mare al englezismelor de a afecta structura interna a limbii romane si de a crea confuzii ortografice grave trebuie importate numai cuvintele englezesti care nu au corespondent in romana (sau al caror corespondent nu poate fi creat din cuvinte romanesti deja existente), iar importarea trebuie insotita de adaptarea cuvintelor la specificul gramaticii romanesti. Exista din pacate impresia larg raspindita ca o limba straina (engleza, in speta) poate fi invatata doar urmarind filme (artistice sau de desene animate) subtitrate si citind materiale scrise existente pe internet. Sigur ca un grad de intelegere a limbii straine se obtine in acest fel, insa el este total necorespunzator si nu ridica pe nimeni la nivelul de cunoscator al limbii in cauza. Invatarea sistematica a limbii este astfel neglijata complet, fiind socotita inutila, ceea ce este o greseala majora. Desigur ca filmele te pot ajuta sa iti faci un bagaj de cuvinte si sa inveti in acelasi timp pronuntia lor, insa ele nu te pot invata sa scrii cuvintele pe care le auzi si cum sa le folosesti pentru a alcatui cu ele propozitii corecte. Invatarea scrisului unei limbi straine citind materiale de pe internet este o mare iluzie, pentru ca majoritatea internautilor citesc doar articole referitoare la informatica, domeniu care foloseste un jargon special, cu un numar limitat de cuvinte, care pe desupra au uneori sensuri diferite fata de utilizarea lor in viata de zi cu zi. Articolele tehnice folosesc de obicei un limbaj sec, adaptat functiei de descriere si explicare, care nu are nici pe departe bogatia limbajului viu folosit in conversatii sau in literatura. Invatarea adevarata presupune stapinirea gramaticii si citirea multor lucrari cu caracter literar, singurele care pot dezvalui bogatia unei limbi, permitind in acelasi timp dezvoltarea capacitatii de a scrie corect. Limba romana este o limba care ii ajuta mult pe scriitori, pentru ca ea permite concentrarea gindirii exclusiv pe continutul ideilor pe care dorim sa le exprimam si lasarea deoparte a grijii pentru corectitudinea ortografica, pentru ca aceasta este implicita. In epoca internetului, in care exprimarea in scris este la indemina tuturor, limba romana este unealta pefecta pentru oricine doreste sa isi descopere si exploateze creativitatea. Sursa: http://muntealb.byethost17.com |