Step 1: Select the right key for your Windows.
Here is the list of Windows 10 volume license keys.
Home: TX9XD-98N7V-6WMQ6-BX7FG-H8Q99 Home N: 3KHY7-WNT83-DGQKR-F7HPR-844BM Home Single Language: 7HNRX-D7KGG-3K4RQ-4WPJ4-YTDFH Home Country Specific: PVMJN-6DFY6-9CCP6-7BKTT-D3WVR Professional: W269N-WFGWX-YVC9B-4J6C9-T83GX Professional N: MH37W-N47XK-V7XM9-C7227-GCQG9 Education: NW6C2-QMPVW-D7KKK-3GKT6-VCFB2 Education N: 2WH4N-8QGBV-H22JP-CT43Q-MDWWJ Enterprise: NPPR9-FWDCX-D2C8J-H872K-2YT43 Enterprise N: DPH2V-TTNVB-4X9Q3-TJR4H-KHJW4
Step 2: Right-click on the start button and open Command Prompt (Admin). Step 3: Use the command “slmgr /ipk yourlicensekey” to install a license key (yourlicensekey is the activation key you got above). (*Note*: You need to hit [Enter] key to execute commands.) Step 4: Use the command “slmgr /skms kms8.msguides.com” to connect to my KMS server. Step 5: The last step is to activate your Windows using the command “slmgr /ato”.
Or use o batch file: Step 1: Copy the following code into a new text document.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@echo off
title Activate Windows 10 ALL versions for FREE!&cls&echo ============================================================================&echo #Project: Activating Microsoft software products for FREE without software&echo ============================================================================&echo.&echo #Supported products:&echo - Windows 10 Home&echo - Windows 10 Home N&echo - Windows 10 Home Single Language&echo - Windows 10 Home Country Specific&echo - Windows 10 Professional&echo - Windows 10 Professional N&echo - Windows 10 Education N&echo - Windows 10 Education N&echo - Windows 10 Enterprise&echo - Windows 10 Enterprise N&echo - Windows 10 Enterprise LTSB&echo - Windows 10 Enterprise LTSB N&echo.&echo.&echo ============================================================================&echo Activating your Windows...&cscript //nologo slmgr.vbs /upk >nul&cscript //nologo slmgr.vbs /cpky >nul&wmic os | findstr /I "enterprise" >nul
cscript //nologo slmgr.vbs /ato | find /i "successfully" && (echo.&echo ============================================================================&echo.&echo #My official blog: MSGuides.com&echo.&echo #How it works: bit.ly/kms-server&echo.&echo #Please feel free to contact me at msguides.com@gmail.com if you have any questions or concerns.&echo.&echo #Please consider supporting this project: donate.msguides.com&echo #Your support is helping me keep my servers running everyday!&echo.&echo ============================================================================&choice /n /c YN /m "Would you like to visit my blog [Y,N]?" & if errorlevel 2 exit) || (echo The connection to my KMS server failed! Trying to connect to another one... & echo Please wait... & echo. & echo. & set /a i+=1 & goto server)
explorer "http://MSGuides.com"&goto halt
:notsupported
echo ============================================================================&echo.&echo Sorry! Your version is not supported.&echo.
:halt
pause >nul
Create a new text document. Step 2: Paste the code into the text file. Then save it as a batch file (named “1click.cmd”). Step 3: Run the batch file as administrator. Done
Source: https://msguides.com
Support for Machine Translation (MT) is done în MemoQ through series of
plugins. Pseudo-translation which is fine,
but limited. Although they’ve enhanced it in Adriatic version. Second
plugin is for Google Translate. There’s not much in terms of
configuration, you set the API key, can specify regex which matches will
be ignored in MT process, and enable option to put the tags from source
at the end of the translation.
Word of advice here. If plugin is enabled and set as preferred in
your client, MT results show up alongside Translation Memory ™ hits in
Translation results pane. So if you spend a lot of time there clicking
through segments it’ll cost you some money. Make sure to uncheck Offer machine-translated results while working in the translation grid or adjust it to your actual needs.
Tags in memoQ, as in other localization tools, serve as placeholders
for source file elements which are wrapping or are placed between text
to be translated. If you translate Word documents your tags will be
mainly formatting. So, if these tags will be placed at the end of
translation, formatting will be broken. Which is maybe not big thing if
you’re using MT as support to human translation, because your translator
will place tags where they belong. Although he probably won’t be very
happy about it. But I’ve wanted to use MT as some kind of self-service
for teams which don’t require quality translations, just want to
understand the text.
Luckily memoQ offers export/import of bilingual files and its native
format is mqxliff which is XML. Each segment
is wrapped in trans-unit tag. Source segment if it contains tags looks like this.
<sourcexml:space="preserve"mq:segpart="8">You can <bptid="1"ctype="underlined">{}</bpt><bptid="2"><hlnk id="rId8" history="1" fileName="document.xml" href="@07c1b597-2ac9-446f-b816-78a8a151172a"></bpt><bptid="3"><rpr id="0"></bpt>download it here for free<eptid="1">{}</ept><eptid="3"></rpr id="0" transform="close"></ept><eptid="2"></hlnk></ept>.</source>
We need to work on XML level as we want these tags encoded back
exactly as they’re now. First we need to get rid of source tags, I don’t
like regex in my code, but this time it’s necessary </?source(.+?)?>. Now we have this.
You can <bptid="1"ctype="underlined">{}</bpt><bptid="2"><hlnk id="rId8" history="1" fileName="document.xml" href="@07c1b597-2ac9-446f-b816-78a8a151172a"></bpt><bptid="3"><rpr id="0"></bpt>download it here for free<eptid="1">{}</ept><eptid="3"></rpr id="0" transform="close"></ept><eptid="2"></hlnk></ept>.
Not bad, but still you don’t want to translate tags, so we’ll split this with another regex (<.+?>.+?</.+?>) to get nice array of strings. And then if item in array starts with < we add it as-is to target tag, else we first MT it.
Of course we could pass it as-is to Google Translate and receive back
translation with tags intact, but then while adding it to original
mqxliff all tags will be escaped, like <bpt id="1" ctype="underlined">.
And after import they’ll appear as regular text in memoQ and will be
exported to DOCX (or whatever was original format) as such. So not only
formatting will be broken, you’ll have garbage text within your
translated text.
Last, but very important, thing. We need to set mq:status attribute for each changed trans-unit tag, so it equals "MachineTranslated".
Otherwise even though we have translation for memoQ it’s empty and on
export it’ll either not be exported or reverted to source text,
depending on your settings.
As I was digging through mqxliff I’ve found another interesting thing. If segment is locked, it has following attributes translate="no" mq:locked="locked".
Apparently, it’s enough to remove them from trans-unit tag and after
import segment will be unlocked in memoQ project. It’s very useful as
currently you need to have PM license to be able to lock/unlock
segments, which is expensive. Plus, it’s tedious task if you need to do
it manually. Source: https://blog.liox.eu
When it comes to online CAT-tools I personally consider Memsource as
one of the better ones – it’s reasonably fast, offers decent
functionality and usability. It’s even better with local (but not
offline) client, which can undock some windows, so you can have
concordance and TM matches on screen at the same time. Still, it’s not
the same as memoQ when it comes to comfort and features, so whenever
possible, I process Memsource files in memoQ – that is, if PM allows to
download .mxliff files for work with local tool.
To do so I’m running pre-translation with relatively low threshold,
download project files and open them in memoQ with another copy in
Memsource for concordance and TB checks. After translation I open the
files in memsource editor and use upload functionality to synchronize
files with the server.
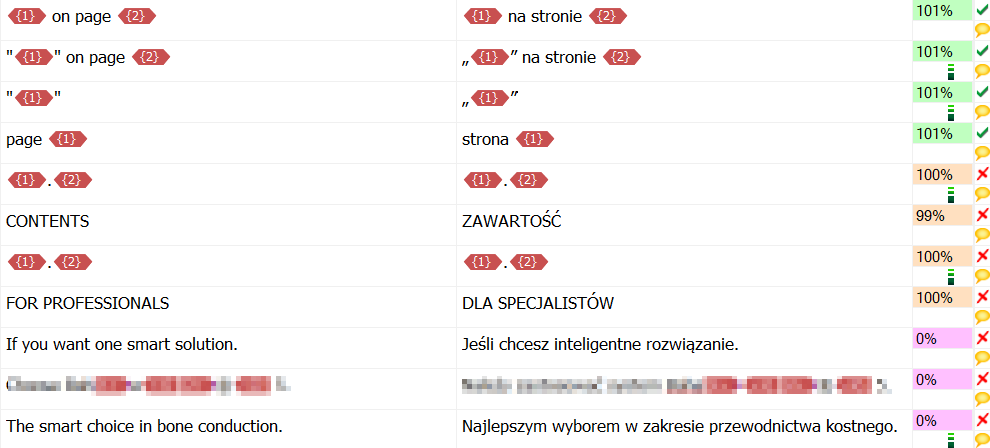
Unfortunately, the XLIFF format is a bit loose when it comes to how
certain features should be implemented, so things like match rate and
translation status are not imported by default and need some tinkering. I
have created a template that can be used to import Memsource files in a
bit more comfortable way.
There is a substantial edit concerning the template:
Originally .mxliff files were modified only before importing
into memoQ, and I left cleaning up extra content to memsource editor.
Now when you export finished translation, extra bits added for memoQ’s compatibility will be removed.
Additionally:
Segments confirmed in memoQ will show as confirmed in Memsource. Of course you should still update the Memsource TM.
Content of “Alt-trans” imported by default to memoQ from Memsource as comment will be ignored now. I
was asked by multiple users to disable this. If you want alternative
translations from Memsource, you can enable them in memoQ filter filter
options.
I removed my export path rules from template settings – this was
causing problems for some users. Still, it’s a good idea to edit export
path rules so memoQ will overwrite original files and you won’t have to
manually re-name files exported from memoQ (to remove defalut “_iso”
target language addition).
Original post content (still valid):
The template work by performing automated actions: the files are
edited with regex-based Find and Replace rules to insert additional
attributes for match rate and segment states (regex rules are included
in .xml configuration files). Subsequently customixed XLIFF filter is
used, configured to recognize the introduced attributes and regex-based
tagging is run to convert Memsource tags into memoQ tags.
To use the template you need to follow instructions below for import
and setup. When everything is configured correctly, you can create
project from template and work with Memsource files more comfortably.
But always remember to back up your files in case something goes wrong.
Also while the conversions and template were tested by two people
without any issues (at the time of publication), I can’t predict every
possible case and setup, so you are doing this at your own risk – if
something goes wrong, I may tray to help, but I won’t be held
responsible. Before you start: the template will work only with memoQ 8.x and 7.8,
not older. However, executable file “FindAndReplace.exe” is only
installed with memoQ version 8.1 and newer. If you have older version,
you need to downloadit separately (see below).
Template Memsource does the following:
match rate will be visible in memoQ
locked status will be kept (segments locked in memsource will be locked in memoQ)
“translated” status will be kept
segments populated with machine translation will have “MT” status in memoQ
memsource tags will be converted into memoQ tags
Preparation:
1. memoQ version 8.1 and newer: none
2. memoQ version 7.8: download and unzip executable FindAndReplace
(alternatively download and install newest memoQ version, you can still
use 7.8, but FindAndReplace will be installed in the default path).
Unzip the content (remember where you unzipped it).
Start memoQ, open Resource console.
Select Filter configurations.
Select Import new and import: ChainedConverter#memsource-tagged.mqres
Select Project templates.
Select Import new > Memsource.mqres
The template contains hard-coded path for configuration file: C:\memoQ\FindAndReplace\memsource.xml.
If you don’t want to edit the template, create this folder and put
“memsource.xml” in this path. Alternatively edit the template:
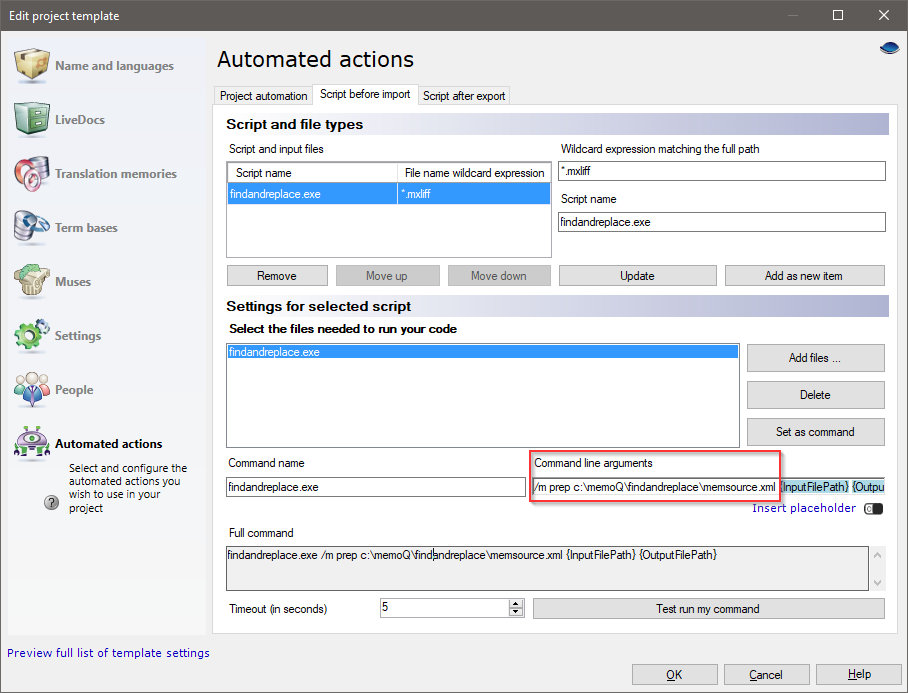
Select Resource console > Templates > memsource with states > Edit > Automated actions > Script before import and edit path in Command line arguments field, then click Update. You can now create template project and import Memsource files.
Tagging mechanism will create empty (single) tags for numbers
enclosed in curly brackets ( {1} ), opening (left) tags for any content
starting with left curly bracket and closed by “greater than” sign (e.g.
{1> or {i> ) and closing (right) tags for any content starting
with “less than” sign closed by right curly bracket (e.g. <1} or
<i} ). However, it is unlikely but possible that incorrect content
will be tagged. In such case please contact me. PRO tip: File extension “mxliff” is not recognized by memoQ, so when you are adding files to memoQ project, you need to “Show all“. But when you create a project based on this template you can skip “Add files” step (just don’t add any files) and when the template-based project is created, simply drag and drop mxliff files into “Translations” memoQ window. Files will be recognized and correct filter will be applied automatically.
To update already installed template you need to:
Using resouce console delete existing filter configuration and project template and install updated version
OR
Using resouce console rename existing filter configuration and project template and install updated version
OR
Import updated filter configuration with new name, import updated
project template with new name and modify it to include updated filter
configuration name.
Please note: the templates reference FindAndReplace.exe file, which should be available at C:\Program Files (x86)\Kilgray\FindAndReplace Tool
folder (for memoQ 8.1 and up). If you have non-standard memoQ
installation path, you need to edit exe configuration in template
settings (see below). If you have memoQ version older than 8.1, you need
to download the file separately and edit the path in template settings:
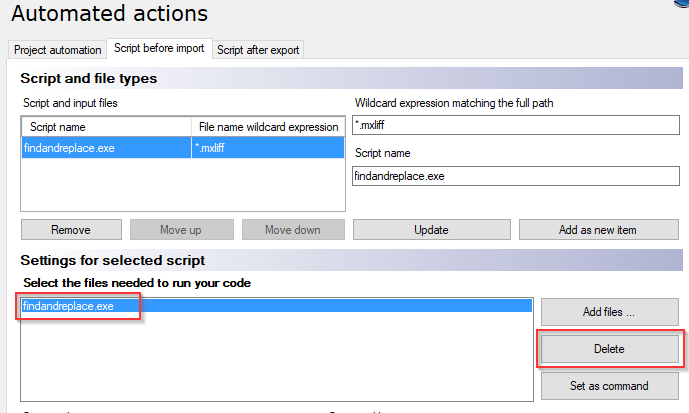
Select Resource console > Templates > memsource with states > Edit > Automated actions > Script before import > Select findandreplace.exe and click Delete.
Click Add files…, browse to and select FindAndReplace.exe.
Click Update.
Template can be further customized with your default languages, TMs, light resources etc.
Additional help for templates with find and replace scripts can be found here: https://help.memoq.com/8-3/en/index.html?edit-template-find-and-replace.html
Template configuration file (actual find and replace commands) is commented and you can customize it any way you like. Source: http://wasaty.pl
1 Deutsche und französische Formen sind mit dem Paket babel und dessen Option (n)german verfügbar. 2 Mnemonische Namen der keysyms des X Window System zur Verwendung mit xmodmap
„
Anführungszeichen (doppelt öffnend)
U+201E
⌥ + ^
Alt + 0132
‚
Anführungszeichen (einfach öffnend)
U+201A
⌥ + S
Alt + 0130
‘
Anführungszeichen (einfach schließend)
U+2018
⌥ + #
Alt + 0145
“
Anführungszeichen (doppelt schließend)
U+201C
⌥ + 2
Alt + 0147
Anführungszeichen werden zum Zitieren von Textpassagen, zur Ironisierung und Distanzierung genutzt. Zur Verschachtelung gibt es einfache und doppelte Anführungszeichen.
»Eselsbrücke: 99 unten, 66 oben!«
Im Deutschen sitzt das öffnende Anführungszeichen unten, weshalb die Verwendung des doppelten Kodierungszeichens gleich doppelt falsch ist: Weder Position noch Form stimmen. Dabei ist die Regel eigentlich ganz einfach: 99 unten, 66 oben! Die Zeichen sind eben nur etwas versteckt …
Die oft verwendeten doppelten Kodierungszeichen haben sowohl die falsche Form als auch die falsche Position. Schrift: FF Bau SuperRobert Bringhurst empfiehlt, möglichst wenig Anführungszeichen zu verwenden und stattdessen – wo sinnvoll – kursiv zu setzen. Auch Jan Tschichold nennt das Anführungszeichen »deutlich wohl, aber nicht gerade satzverschönernd« (Schriften 1947–1974 Band 2, S. 185).
Warum nicht einfach "so"?
Es läge nahe – Jeder macht es, man hat sich schon fast daran gewöhnt und am schnellsten geht es auch noch, da die doppelten Kodierungszeichen – Schreibmaschine sei Dank – über Umschalt + 2 einfach zu erreichen ist. Fast alle Quellen heben nur den Zeigefinger und erklären, dass es falsch ist, aber warum es falsch ist, erklärt eigentlich nur Hans Peter Willberg (Typolemik, S. 127): Es führt schlicht und einfach zu Verwirrung; Man verliert den Überblick, wo gerade wörtliche Rede anfängt und wo sie aufhört. Und alles, was das störungsfreie Lesen behindert, widerspricht dem Sinn der Typografie: dem Leser dienen.
'
Einfaches Kodierungszeichen
U+0027
⇧ + #
⇧ + #
"
Doppeltes Kodierungszeichen
U+0022
⇧ + 2
⇧ + 2
Guillemets – Die elegante Variante
»
Guillemet (doppelt öffnend)
U+00BB
⌥ + ⇧ + Q
Alt + 0187
›
Guillemet (einfach öffnend)
U+203A
⇧ + ⌥ + N
Alt + 0155
‹
Guillemet (einfach schließend)
U+2039
⇧ + ⌥ + B
Alt + 0139
«
Guillemet (doppelt schließend)
U+00AB
⌥ + Q
Alt + 0171
Die »französischen« Anführungszeichen werden nach ihrem wahrscheinlichen Erfinder Guillaume Le Bé auch Guillemets (»kleine Willis«) genannt. Im Deutschen werden sie im Gegensatz zum Französischen und Schweizerischen »nach innen zeigend« verwendet, obwohl grundsätzlich auch nichts gegen die umgekehrte Verwendung spricht.
Im Deutschen werden die Guillemets – im Gegensatz zum Französischen – nach innen zeigend verwendet. Schrift: Ingeborg Fat Italic Ihr großer Vorteil gegenüber den Gänsefüßchen liegt darin, dass sie durch ihre Form weniger Luft um sich herum haben und somit keine störenden Löcher in den Text reißen. Das kommt dem typografischen Grundsatz eines möglichst ruhigen Satzbildes entgegen, so dass sie z. B. in Büchern der Quasi-Standard sind.
Um die Störung zu minimieren, empfiehlt Jan Tschichold gar die Verwendung von einzelnen Guillemets als primäre Anführungszeichen nach dem Schema ‹–«–»–›. (Schriften 1947–1974 Band 2, S. 185)
Beim Satz mit gebrochener Schrift sollten keine Guillemets verwendet werden.
Verschachtelung
Soll beispielsweise wörtliche Rede innerhalb eines Zitats dargestellt werden, greift man auf die einfache Variante des Anführungszeichens zurück. Auch hier haben die »französischen« Anführungszeichen einen Vorteil, da hier keine Verwechselungsgefahr mit Komma oder Apostroph besteht.
Andere Länder, andere Zeichen
“
Englisch, öffnend
U+201C
⌥ + 2
Alt + 0147
‘
Englisch, einfach öffnend
U+2018
⌥ + #
Alt + 0145
’
Englisch, einfach schließend
U+2019
⇧ + ⌥ + #
Alt + 0146
”
Englisch, schließend
U+201D
⇧ + ⌥ + 2
Alt + 0148
Jedes Land hat seine eigenen orthografischen Besonderheiten, und an Details wie den richtigen landesspezifischen Anführungszeichen erkennt man den sorgfältigen Typografen. Wikipedia bietet eine gute Übersicht.
»Eselsbrücke für englische Anführungszeichen: 66 oben, 99 oben!«
Gern werden im Deutschen die doppelten Kodierungszeichen (»Zollzeichen«) fälschlicherweise als englische Anführungszeichen angesehen und dementsprechend durchgehen gelassen. Aber auch wenn die Position (vorne und hinten oben) die gleiche ist, sind die Zeichen im englischsprachigen Raum ebenso falsch wie hier. Die Eselsbrücke für die englischen Anführungszeichen ist genau anders herum wie die deutsche – 66 oben, 99 oben: Der Engländer öffnet, womit der Deutsche schließt.
Der Engländer öffnet, womit der Deutsche schließt. (Schrift: Studio Slant)
Fremdsprachliche Zitate in deutschem Text
Kurze fremdsprachliche Zitate sollten dieselben Anführungszeichen wie der umgebende Text erhalten, wohingegen man längere Passagen ruhig mit den landesspezifischen Anführungszeichen versehen kann.
˝
Doppelakut
U+02DD
⇧ + ⌥ + T
—
"
Doppeltes Kodierungszeichen
U+0022
⇧ + 2
⇧ + 2
″
Zoll-/ Sekundenzeichen
U+2033
—
—
>
Größer als
U+003E
⇧ + <
⇧ + <
Alle gezeigten Zeichen sind keine Anführungszeichen; Der Doppelakut ist ein ungarischer Akzent, das doppelte Kodierungszeichen ist ein Überbleibsel der Schreibmaschine und außerhalb von Programmcode allenfalls als Ersatz für das schwer erreichbare und selten vorhandene Zollzeichen zu gebrauchen. Auch ein beliebter Fehler: Kleiner-als und Größer-als zweimal hintereinander als Guillemets benutzen. Autsch.
Anführungszeichen und optische Achsen
Eine durchgehende linke Achse beruhigt das Satzbild und trägt somit zur besseren Lesbarkeit eines Textes bei. Deshalb sollten öffnende Anführungszeichen, die diese Achse stören, besser außerhalb plaziert werden.
Nicht nur Robert Gernhardts Wal-Episode aus den Animalerotica macht sich wesentlich besser, wenn die linke Achse nicht gestört wird. (Schrift: Caecilia Light)
Anführungszeichen und Kerning
Gänsefüßchen sind durch ihre Form prädestiniert dazu, in Kombination mit anderen Buchstaben Löcher und Kollisionen zu verursachen. Deshalb sollte sichergestellt werden, dass der Font, den man verwenden möchte, sorgfältig gekernt ist; am besten mit dem Typefacts-Kerningtest.
PS: Vorne anführen, hinten abführen?
Statt »Abführungszeichen« sollte man laut Detailtypografie besser »Schlußzeichen« oder »Ausführungszeichen« sagen … Source: https://typefacts.com
Anführungszeichen sind Interpunktionszeichen; Satzausdruckzeichen. Im Volksmund auch »Gänsefüße« oder »Gänsefüßchen« genannt. Optische Auszeichnung1 ) von wörtlich wiedergegebenen Äußerungen (direkter Rede) und Textstellen (Zitate) sowie zur Hervorhebung von Wortteilen, Wörtern oder Satzteilen (z.B. Buchtitel, Sprichwörter oder ironische Äußerungen).
Anführungszeichen stehen vor und nach dem ausgezeichneten Wort oder der ausgezeichneten Textpassage. Das eröffnende Anführungszeichen wird als »Anführung«, das schließende Anführungszeichen als »Abführung« bezeichnet. Wird in eine Anführung eine andere Anführung eingeschoben, so erhält diese ein halbes Anführungszeichen. 2 )
Das »Anführungzeichen« ist ein Interpunktionszeichen. Der Stand des orthographischen Satzzeichens ist – hier in der deutschen Variante (unten/oben) – anhand der vier Hauptschriftlinien und der hp-Vertikalhöhe skizziert, wobei es von Schrift zu Schrift zu Abweichungen kommt. Beispiel gesetzt in der »Microsoft Sans Serif«, einer Systemschrift von Microsoft®.Die Verwendung von Anführungszeichen werden in Deutschland entsprechend den Empfehlungen des Rats für deutsche Rechtschreibung geregelt. 3 )4 )
Typografische Anführungszeichen stammen aus der Antiqua-Tradition der Spätrenaissance, welche sich vermutlich aus den Kolumnenkommentaren entwickelt haben. Typografische Anführungszeichen dienten ursprünglich dazu, in lateinisch oder altgriechisch abgefassten Texten Passagen aus anderen Sprachen sowie wörtliche und sinngemäße Zitate zu kennzeichnen. 5 )
Positionen (Stellungen) von Anführungszeichen
Deutsche Anführungszeichen (Umgangssprachlich auch Gänsefüßchen genannt)
‚‚hamburgerfontsitiv‘‘ (unten/oben) 6 )
Englische bzw. Angloamerikanische Anführungszeichen
″hamburgerfontsitiv″ (Oben/Oben, zwischen k-Linie und x-Linie, optisch ausgerichtet an der H-Linie)
Französische Anführungszeichen (Guillemets français)
« hamburgerfontsitiv » (Mitte/Mitte, zwischen x-Linie und Grundlinie sowie je ein Leerzeichen bzw. 1/4 Geviert Zwischenraum nach dem Guillemet ouvrant (vor dem angeführten Wort) bzw. vor dem Guillemet fermant (nach dem angeführten Wort). 7 )
Umgekehrte französische Anführungszeichen (Deutschland und Österreich)
»hamburgerfontsitiv« (Mitte/Mitte, Spitze nach innen, zwischen x-Linie und Grundlinie ohne Leerzeichen)
Umgekehrte französische Anführungszeichen (Deutschsprachige Schweiz)
«hamburgerfontsitiv» (Mitte/Mitte, Spitze nach außen, zwischen x-Linie und Grundlinie ohne Leerzeichen)
Formen (Figuren) von Anführungszeichen
Eine verbindliche Richtlinie für die Zeichenform bzw. Figur des Interpunktionszeichens im deutschen Schriftsatz existiert nicht. 8 ) Nur die Position des Satzausdruckzeichens ist im typografischen Schriftsatz geregelt. Je nach Schriftgattung und Schriftstil sind somit unterschiedliche Figuren des Anführungszeichens möglich: Zwei gerade vertikale Striche oder abgeschrägte Striche mit oder ohne Auslaufpunkt oder Tropfen sowie runde Varianten.
Beispiele unterschiedlicher Formen von An- und Abführungen. Von oben: Celeste, Meta+, Thonburi, DIN Schrift, Matrix Script und Garamont Amsterdam.Die englische bzw. angloamerikanische Form – nicht Position – der Satzausdruckzeichen, in Deutschland umgangssprachlich mit »99/66« skizziert, ist nur im englischsprachigen Schriftsatz üblich, um eine Verwechslung mit den dort gebräuchlichen Kürzeln für Zoll, Sekunden und Bogensekunden – ein und zwei vertikale Striche auf halber Höhe zwischen x- und H-Linie bzw. k-Linie (siehe Schriftlinien), teilweise nach unten verjüngt – zu vermeiden. Im frühen 18. Jahrhundert wurden aus diesem Grund die Anführungszeichen in England – und somit auch in Nordamerika – mit einem Tropfen versehen und der Fortlauf (Hybrid aus Punkt und Komma) abgeschrägt. 9 )
Im Zuge der digitalen Schriftübermittlung geht diese angloamerikanische Tradition zur Zeit verloren, da viele Screen Fonts, wie die von Matthew Carter für Microsoft® gestaltete »Verdana«, (z.B. in der Erstversion) keine englischen Antiqua-Anführungszeichen im Standardzeichenrepertoire (exklusive Glyphen) mehr führen. 10 ) Insbesondere serifenlose Screen Fonts führen mehrheitlich nur noch ein »gerades Anführungszeichen«, das dem englischen Zollzeichen gleicht.
Tipp: Bei freigestellten Zitaten wird die Anführung – egal ob es sich um Deutsche, Englische oder Französische Anführungszeichen handelt, immer zugunsten des Optischen Randausgleichs über die linke Satzkante gestellt.In der Buchtypografie gelten Französischen Anführungszeichen als die schönste und best lesbare Formvariante aller An- und Abführungszeichen, da sie keine Lücken im Schriftsatz verursacht oder Verwechslungen mit anderen Schriftzeichen, beispielsweise einem Zollzeichen, ausschließt. 11 )
PC-Tastaturbelegung
Anführungszeichen sind über eine PC-Standardtastatur, z.B. nach DIN 2137-T2, singulär oder mit einer Tastenkombination eintippbar. Für die Zeichencodierung existieren unterschiedliche ISO-Normen. 12 )




 – anhand der vier Hauptschriftlinien und der hp-Vertikalhöhe skizziert, wobei es von Schrift zu Schrift zu Abweichungen kommt. Beispiel gesetzt in der »Microsoft Sans Serif«, einer Systemschrift von Microsoft®.")





