The world of relational database theory is a world dominated by tables and sets, and operations on tables and sets. A database is a set of tables, and a table is a set of rows and columns. When you issue a SELECT statement to retrieve rows from a table, you get back another set of rows and columns—that is, another table. These are abstract notions that make no reference to the underlying representation a database system uses to operate on the data in your tables. Another abstraction is that operations on tables happen all at once; queries are conceptualized as set operations and there is no concept of time in set theory.
The real world, of course, is quite different. Database management systems implement abstract concepts but do so on real hardware bound by real physical constraints. As a result, queries take time—sometimes an annoyingly long time. And we, being impatient creatures, don't like to wait, so we leave the abstract world of instantaneous mathematical operations on sets and look around for ways to speed up our queries. Fortunately, there are several techniques for doing so:
-
We index tables to allow the database server to look up rows more
quickly.
-
We consider how to write queries to take advantage of those
indexes to
the fullest extent, and use the EXPLAIN statement to
check whether
the MySQL server really is doing so.
-
We write queries to affect the server's scheduling mechanism so
that
queries arriving from multiple clients cooperate better.
-
We modify the server's operating parameters to get it to perform
more efficiently. We think about what's going on with the
underlying
hardware and how we can work around its physical constraints to
improve
performance.
Using Indexing
Indexing is the most important tool you have for speeding up queries. Other techniques are available to you, too, but generally the one thing that makes the most difference is the proper use of indexes. On the MySQL mailing list, people often ask for help in making a query run faster. In a surprisingly large number of cases, there are no indexes on the tables in question, and adding indexes often solves the problem immediately. It doesn't always work like that, because optimization isn't always simple. Nevertheless, if you don't use indexes, in many cases you're just wasting your time trying to improve performance by other means. Use indexing first to get the biggest performance boost and then see what other techniques might be helpful.This section describes what an index is and how indexing improves query performance. It also discusses the circumstances under which indexes might degrade performance and provides guidelines for choosing indexes for your table wisely. In the next section, we'll discuss MySQL's query optimizer that attempts to find the most efficient way to execute queries. It's good to have some understanding of the optimizer in addition to knowing how to create indexes because then you'll be better able to take advantage of the indexes you create. Certain ways of writing queries actually prevent your indexes from being useful, and generally you'll want to avoid having that happen.
Benefits of Indexing
Let's consider how an index works by beginning with a table that has no indexes. An unindexed table is simply an unordered collection of rows. For example, Figure 4.1 shows the ad table that was discussed in Chapter 1, "Getting Started with MySQL and SQL." There are no indexes on this table, so to find the rows for a particular company, it's necessary to examine each row in the table to see if it matches the desired value. This involves a full table scan, which is slow, as well as tremendously inefficient if the table is large but contains only a few records that match the search criteria.Figure 4.2 shows the same table, but with the addition of an index on the company_num column in the ad table. The index contains an entry for each row in the ad table, but the index entries are sorted by company_num value. Now, instead of searching through the table row by row looking for items that match, we can use the index. Suppose that we're looking for all rows for company 13. We begin scanning the index and find three values for that company. Then we reach the index value for company 14, which is higher than the one we're looking for. Index values are sorted, so when we read the index record containing 14, we know we won't find any more matches and can quit looking. Thus, one efficiency gained by using the index is that we can tell where the matching rows end and can skip the rest. Another efficiency comes about through the use of positioning algorithms for finding the first matching entry without doing a linear scan from the start of the index (for example, a binary search is much quicker than a scan). That way, we can quickly position to the first matching value and save a lot of time in the search. Databases use various techniques for positioning to index values quickly, but it's not so important here what those techniques are. What's important is that they work and that indexing is a good thing.
You might be asking why we don't just sort the data rows and dispense with the index. Wouldn't that produce the same type of improvement in search speed? Yes, it would—if the table had a single index. But you might want to add a second index, and you can't sort the data rows two different ways at once. (For example, you might want one index on customer names and another on customer ID numbers or phone numbers.) Using indexes as entities separate from the data rows solves the problem and allows multiple indexes to be created. In addition, rows in the index are generally shorter than data rows. When you insert or delete new values, it's easier to move around shorter index values to maintain the sort order than to move around the longer data rows.
)
)
The particular details of index implementations vary for different MySQL storage engines. For example, for a MyISAM table, the table's data rows are kept in a data file, and index values are kept in an index file. You can have more than one index on a table, but they're all stored in the same index file. Each index in the index file consists of a sorted array of key records that are used for fast access into the data file.
By contrast, the BDB and InnoDB storage engines do not separate data rows and index values in the same way, although both maintain indexes as sets of sorted values. By default, the BDB engine uses a single file per table to store both data and index values. The InnoDB engine uses a single tablespace within which it manages data and index storage for all InnoDB tables. InnoDB can be configured to create each table with its own tablespace, but even so, a table's data and indexes are stored in the same tablespace file.
The preceding discussion describes the benefit of an index in the context of single-table queries, where the use of an index speeds searches significantly by eliminating the need for full table scans. Indexes are even more valuable when you're running queries involving joins on multiple tables. In a single-table query, the number of values you need to examine per column is the number of rows in the table. In a multiple-table query, the number of possible combinations skyrockets because it's the product of the number of rows in the tables.
Suppose that you have three unindexed tables, t1, t2, and t3, each containing a column i1, i2, and i3, respectively, and each consisting of 1,000 rows that contain the numbers 1 through 1000. A query to find all combinations of table rows in which the values are equal looks like this:
SELECT t1.i1, t2.i2, t3.i3 FROM t1, t2, t3 WHERE t1.i1 = t2.i2 AND t2.i1 = t3.i3;The result of this query should be 1,000 rows, each containing three equal values. If we process the query in the absence of indexes, we have no idea which rows contain which values without scanning them all. Consequently, we must try all combinations to find the ones that match the WHERE clause. The number of possible combinations is 1,000 x 1,000 x 1,000 (one billion!), which is a million times more than the number of matches. That's a lot of wasted effort. The example illustrates that as tables grow, the time to process joins on those tables grows even more if no indexes are used, leading to very poor performance. We can speed things up considerably by indexing the tables, because the indexes allow the query to be processed like this:
- Select the first row from table t1 and see what value the row contains.
- Using the index on table t2, go directly to the row that matches the value from t1. Similarly, using the index on table t3, go directly to the row that matches the value from t2.
- Proceed to the next row of table t1 and repeat the preceding procedure. Do this until all rows in t1 have been examined.
MySQL uses indexes in several ways:
- As just described, indexes are used to speed up searches for rows matching terms of a WHERE clause or rows that match rows in other tables when performing joins.
- For queries that use the MIN() or MAX() functions, the smallest or largest value in an indexed column can be found quickly without examining every row.
- MySQL can often use indexes to perform sorting and grouping operations quickly for ORDER BY and GROUP BY clauses.
- Sometimes MySQL can use an index to reading all the information required for a query. Suppose that you're selecting values from an indexed numeric column in a MyISAM table, and you're not selecting other columns from the table. In this case, when MySQL reads an index value from the index file, it obtains the same value that it would get by reading the data file. There's no reason to read values twice, so the data file need not even be consulted.
Costs of Indexing
In general, if MySQL can figure out how to use an index to process a query more quickly, it will. This means that, for the most part, if you don't index your tables, you're hurting yourself. You can see that I'm painting a rosy picture of the benefits of indexing. Are there disadvantages? Yes, there are. There are costs both in time and in space. In practice, these drawbacks tend to be outweighed by the advantages, but you should know what they are.First, indexes speed up retrievals but slow down inserts and deletes, as well as updates of values in indexed columns. That is, indexes slow down most operations that involve writing. This occurs because writing a record requires writing not only the data row, it requires changes to any indexes as well. The more indexes a table has, the more changes need to be made, and the greater the average performance degradation. In the section "Loading Data Efficiently," we'll go into more detail about this phenomenon and what you can do about it.
Second, an index takes up disk space, and multiple indexes take up correspondingly more space. This might cause you to reach a table size limit more quickly than if there are no indexes:
- For a MyISAM table, indexing it heavily may cause the index file to reach its maximum size more quickly than the data file.
- For BDB tables, which store data and index values together in the same file, adding indexes causes the table to reach the maximum file size more quickly.
- All InnoDB tables that are located within the InnoDB shared tablespace compete for the same common pool of space, and adding indexes depletes storage within this tablespace more quickly. However, unlike the files used for MyISAM and BDB tables, the InnoDB shared tablespace is not bound by your operating system's file-size limit, because it can be configured to use multiple files. As long as you have additional disk space, you can expand the tablespace by adding new components to it. InnoDB tables that use individual tablespaces are constrained the same way as BDB tables because data and index values are stored together in a single file.
Choosing Indexes
The syntax for creating indexes is covered in the section "Creating Indexes," of Chapter 2, "MySQL SQL Syntax and Use." I assume here that you've read that section. But knowing syntax doesn't in itself help you determine how your tables should be indexed. That requires some thought about the way you use your tables. This section gives some guidelines on how to identify candidate columns for indexing and how best to set up indexes:Index columns that you use for searching, sorting, or grouping, not columns you only display as output. In other words, the best candidate columns for indexing are the columns that appear in your WHERE clause, columns named in join clauses, or columns that appear in ORDER BY or GROUP BY clauses. Columns that appear only in the output column list following the SELECT keyword are not good candidates:
SELECT col_a <- not a candidate FROM tbl1 LEFT JOIN tbl2 ON tbl1.col_b = tbl2.col_c <- candidates WHERE col_d = expr; <- a candidateThe columns that you display and the columns you use in the WHERE clause might be the same, of course. The point is that appearance of a column in the output column list is not in itself a good indicator that it should be indexed.
Columns that appear in join clauses or in expressions of the form col1 = col2 in WHERE clauses are especially good candidates for indexing. col_b and col_c in the query just shown are examples of this. If MySQL can optimize a query using joined columns, it cuts down the potential table-row combinations quite a bit by eliminating full table scans.
Consider column cardinality. The cardinality of a column is the number of distinct values that it contains. For example, a column that contains the values 1, 3, 7, 4, 7, and 3 has a cardinality of four. Indexes work best for columns that have a high cardinality relative to the number of rows in the table (that is, columns that have many unique values and few duplicates). If a column contains many different age values, an index will differentiate rows readily. An index will not help for a column that is used to record sex and contains only the two values 'M' and 'F'. If the values occur about equally, you'll get about half of the rows whichever value you search for. Under these circumstances, the index might never be used at all, because the query optimizer generally skips an index in favor of a full table scan if it determines that a value occurs in a large percentage of a table's rows. The conventional wisdom for this percentage used to be "30%." Nowadays the optimizer is more complex and takes other factors into account, so the percentage is not the sole determinant of when MySQL prefers a scan over using an index.
Index short values. Use smaller data types when possible. For example, don't use a BIGINT column if a MEDIUMINT is large enough to hold the values you need to store. Don't use CHAR(100) if none of your values are longer than 25 characters. Smaller values improve index processing in several ways:
- Shorter values can be compared more quickly, so index lookups are faster.
- Smaller values result in smaller indexes that require less disk I/O.
- With shorter key values, index blocks in the key cache hold more key values. MySQL can hold more keys in memory at once, which improves the likelihood of locating key values without reading additional index blocks from disk.
Index prefixes of string values. If you're indexing a string column, specify a prefix length whenever it's reasonable to do so. For example, if you have a CHAR(200) column, don't index the entire column if most values are unique within the first 10 or 20 characters. Indexing the first 10 or 20 characters will save a lot of space in the index, and probably will make your queries faster as well. By indexing shorter values, you gain the advantages described in the previous item relating to comparison speed and disk I/O reduction. You want to use some common sense, of course. Indexing just the first character from a column isn't likely to be that helpful because then there won't be very many distinct values in the index.
You can index prefixes of CHAR, VARCHAR, BINARY, VARBINARY, BLOB, and TEXT columns. The syntax is described in "Creating Indexes," in Chapter 2.
Take advantage of leftmost prefixes. When you create an n-column composite index, you actually create n indexes that MySQL can use. A composite index serves as several indexes because any leftmost set of columns in the index can be used to match rows. Such a set is called a "leftmost prefix." (This is different from indexing a prefix of a column, which is using the first n characters of the column for index values.)
Suppose that you have a table with a composite index on columns named state, city, and zip. Rows in the index are sorted in state/city/zip order, so they're automatically sorted in state/city order and in state order as well. This means that MySQL can take advantage of the index even if you specify only state values in a query, or only state and city values. Thus, the index can be used to search the following combinations of columns:
state, city, zip state, city stateMySQL cannot use the index for searches that don't involve a leftmost prefix. For example, if you search by city or by zip, the index isn't used. If you're searching for a given state and a particular ZIP code (columns 1 and 3 of the index), the index can't be used for the combination of values, although MySQL can narrow the search using the index to find rows that match the state.
Don't over-index. Don't index everything in sight based on the assumption "the more, the better." That's a mistake. Every additional index takes extra disk space and hurts performance of write operations, as has already been mentioned. Indexes must be updated and possibly reorganized when you modify the contents of your tables, and the more indexes you have, the longer this takes. If you have an index that is rarely or never used, you'll slow down table modifications unnecessarily. In addition, MySQL considers indexes when generating an execution plan for retrievals. Creating extra indexes creates more work for the query optimizer. It's also possible (if unlikely) that MySQL will fail to choose the best index to use when you have too many indexes. Maintaining only the indexes you need helps the query optimizer avoid making such mistakes.
If you're thinking about adding an index to a table that is already indexed, consider whether the index you're thinking about adding is a leftmost prefix of an existing multiple-column index. If so, don't bother adding the index because, in effect, you already have it. (For example, if you already have an index on state, city, and zip, there is no point in adding an index on state.)
Match index types to the type of comparisons you perform. When you create an index, most storage engines choose the index implementation they Match index types to the type of comparisons you perform. When you create an index, most storage engines choose the index implementation they will use. For example, InnoDB always uses B-tree indexes. MySQL also uses B-tree indexes, except that it uses R-tree indexes for spatial data types. However, the MEMORY storage engine supports hash indexes and B-tree indexes, and allows you to select which one you want. To choose an index type, consider what kind of comparison operations you plan to perform on the indexed column:
-
For a hash index, a hash function is applied to each column
value. The
resulting hash values are stored in the index and used to perform
lookups.
(A hash function implements an algorithm that is likely to produce
distinct
hash values for distinct input values. The advantage of using hash
values
is that they can be compared more efficiently than the original
values.)
Hash indexes are very fast for exact-match comparisons performed
with the = or <=> operators.
But they are poor for comparisons that look for a range of values,
as in
these expressions:
id < 30 weight BETWEEN 100 AND 150
CREATE TABLE lookup ( id INT NOT NULL, name CHAR(20), PRIMARY KEY USING BTREE (id) ) ENGINE = MEMORY;If the types of statements that you expect to execute warrant it, a single MEMORY table can have both hash indexes and B-tree indexes, even on the same column.
Some types of comparisons cannot use indexes. If you perform comparisons only by passing column values to a function such as STRCMP(), there is no value in indexing it. The server must evaluate the function value for each row, which precludes use of an index on the column.
Use the slow-query log to identify queries that may be performing badly. This log can help you find queries that might benefit from indexing. You can view this log directly (it is written as a text file), or use the mysqldumpslow utility to summarize its contents. (See Chapter 11, "General MySQL Administration," for a discussion of MySQL's log files.) If a given query shows up over and over in the slow-query log, that's a clue you've found a query that might not be written optimally. You may be able to rewrite it to make it run more quickly. Keep in mind when assessing your slow-query log that "slow" is measured in real time, so more queries will show up in the slow-query log on a heavily loaded server than on a lightly loaded one.
The MySQL Query Optimizer
When you issue a query that selects rows, MySQL analyzes it to see if any optimizations can be used to process the query more quickly. In this section, we'll look at how the query optimizer works. For additional information about optimization measures that MySQL takes, consult the optimization chapter in the MySQL Reference Manual.The MySQL query optimizer takes advantage of indexes, of course, but it also uses other information. For example, if you issue the following query, MySQL will execute it very quickly, no matter how large the table is:
SELECT * FROM tbl_name WHERE 0;In this case, MySQL looks at the WHERE clause, realizes that no rows can possibly satisfy the query, and doesn't even bother to search the table. You can see this by issuing an EXPLAIN statement, which tells MySQL to display some information about how it would execute a SELECT query without actually executing it.1 To use EXPLAIN, just put the word EXPLAIN in front of the SELECT statement:
mysql> EXPLAIN SELECT * FROM tbl_name WHERE 0\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra: Impossible WHERE
Normally, EXPLAIN returns more information than that,
including non-NULL information
about the indexes that will be used to scan tables, the types of joins
that
will be used, and estimates of the number of rows that will need to be
examined
from each table.How the Optimizer Works
The MySQL query optimizer has several goals, but its primary aims are to use indexes whenever possible and to use the most restrictive index in order to eliminate as many rows as possible as soon as possible. That last part might sound backward and nonintuitive. After all, your goal in issuing a SELECT statement is to find rows, not to reject them. The reason the optimizer tries to reject rows is that the faster it can eliminate rows from consideration, the more quickly the rows that do match your criteria can be found. Queries can be processed more quickly if the most restrictive tests can be done first. Suppose that you have a query that tests two columns, each of which has an index on it:SELECT col3 FROM mytable WHERE col1 = 'some value' AND col2 = 'some other value';Suppose also that the test on col1 matches 900 rows, the test on col2 matches 300 rows, and that both tests together succeed on 30 rows. Testing col1 first results in 900 rows that must be examined to find the 30 that also match the col2 value. That's 870 failed tests. Testing col2 first results in 300 rows that must be examined to find the 30 that also match the col1 value. That's only 270 failed tests, so less computation and disk I/O is required. As a result, the optimizer will test col2 first because doing so results in less work overall.
You can help the optimizer take advantage of indexes by using the following guidelines:
Try to compare columns that have the same data type. When you use indexed columns in comparisons, use columns that are of the same type. Identical data types will give you better performance than dissimilar types. For example, INT is different from BIGINT. CHAR(10) is considered the same as CHAR(10) or VARCHAR(10) but different from CHAR(12) or VARCHAR(12). If the columns you're comparing have different types, you can use ALTER TABLE to modify one of them so that the types match.
Try to make indexed columns stand alone in comparison expressions. If you use a column in a function call or as part of a more complex term in an arithmetic expression, MySQL can't use the index because it must compute the value of the expression for every row. Sometimes this is unavoidable, but many times you can rewrite a query to get the indexed column to appear by itself.
The following WHERE clauses illustrate how this works. They are equivalent arithmetically, but quite different for optimization purposes:
WHERE mycol < 4 / 2 WHERE mycol * 2 < 4For the first line, the optimizer simplifies the expression 4/2 to the value 2, and then uses an index on mycol to quickly find values less than 2. For the second expression, MySQL must retrieve the value of mycol for each row, multiply by 2, and then compare the result to 4. In this case, no index can be used. Each value in the column must be retrieved so that the expression on the left side of the comparison can be evaluated.
Let's consider another example. Suppose that you have an indexed column date_col. If you issue a query such as the one following, the index isn't used:
SELECT * FROM mytbl WHERE YEAR(date_col) < 1990;The expression doesn't compare 1990 to an indexed column; it compares 1990 to a value calculated from the column, and that value must be computed for each row. As a result, the index on date_col is not used because performing the query requires a full table scan. What's the fix? Just use a literal date, and then the index on date_col can be used to find matching values in the columns:
WHERE date_col < '1990-01-01'But suppose that you don't have a specific date. You might be interested instead in finding records that have a date that lies within a certain number of days from today. There are several ways to express a comparison of this type—not all of which are equally efficient. Here are three possibilities:
WHERE TO_DAYS(date_col) - TO_DAYS(CURDATE()) < cutoff WHERE TO_DAYS(date_col) < cutoff + TO_DAYS(CURDATE()) WHERE date_col < DATE_ADD(CURDATE(), INTERVAL cutoff DAY)For the first line, no index is used because the column must be retrieved for each row so that the value of TO_DAYS(date_col) can be computed. The second line is better. Both cutoff and TO_DAYS(CURDATE()) are constants, so the right-hand side of the comparison can be calculated by the optimizer once before processing the query, rather than once per row. But the date_col column still appears in a function call, preventing use of the index. The third line is best of all. Again, the right-hand side of the comparison can be computed once as a constant before executing the query, but now the value is a date. That value can be compared directly to date_col values, which no longer need to be converted to days. In this case, the index can be used.
Don't use wildcards at the beginning of a LIKE pattern. Some string searches use a WHERE clause of the following form:
WHERE col_name LIKE '%string%'That's the correct thing to do if you want to find a string no matter where it occurs in the column. But don't put '%' on both sides of the string simply out of habit. If you're really looking for the string only when it occurs at the beginning of the column, leave out the first '%'. Suppose that you're looking in a column containing last names for names like MacGregor or MacDougall that begin with 'Mac'. In that case, write the WHERE clause like this:
WHERE last_name LIKE 'Mac%'The optimizer looks at the literal initial part of the pattern and uses the index to find rows that match as though you'd written the following expression, which is in a form that allows an index on last_name to be used:
WHERE last_name >= 'Mac' AND last_name < 'Mad'This optimization does not apply to pattern matches that use the REGEXP operator. REGEXP expressions are never optimized.
Help the optimizer make better estimates about index effectiveness. By default, when you compare values in indexed columns to a constant, the optimizer assumes that key values are distributed evenly within the index. The optimizer will also do a quick check of the index to estimate how many entries will be used when determining whether the index should be used for constant comparisons. For MyISAM, InnoDB, and BDB tables, you can tell the server to perform an analysis of key values by using ANALYZE TABLE. This provides the optimizer with better information.
Use EXPLAIN to verify optimizer operation. The EXPLAIN statement can tell you whether indexes are being used. This information is helpful when you're trying different ways of writing a statement or checking whether adding indexes actually will make a difference in query execution efficiency. For examples, see "Using EXPLAIN to Check Optimizer Operation."
Give the optimizer hints when necessary. Normally, the MySQL optimizer considers itself free to determine the order in which to scan tables to retrieve rows most quickly. On occasion, the optimizer will make a non-optimal choice. If you find this happening, you can override the optimizer's choice using the STRAIGHT_JOIN keyword. A join performed with STRAIGHT_JOIN is like a cross join but forces the tables to be joined in the order named in the FROM clause.
STRAIGHT_JOIN can be specified at two points in a SELECT statement. You can specify it between the SELECT keyword and the selection list to have a global effect on all cross joins in the statement, or you can specify it in the FROM clause. The following two statements are equivalent:
SELECT STRAIGHT_JOIN ... FROM t1, t2, t3 ... ; SELECT ... FROM t1 STRAIGHT_JOIN t2 STRAIGHT_JOIN t3 ... ;Run the query both with and without STRAIGHT_JOIN; MySQL might have some good reason not to use indexes in the order you think is best. (Check the execution plans with EXPLAIN to see how MySQL handles each statement.)
You can also use FORCE INDEX, USE INDEX, or IGNORE INDEX to give the server guidance about which indexes to prefer.
Take advantage of areas in which the optimizer is more mature. MySQL can do joins and subqueries, but subquery support is more recent, having been added in MySQL 4.1. Consequently, the optimizer has been better tuned for joins than for subqueries in some cases. This has a practical implication when you have a subquery that runs slowly. As discussed in "Rewriting Subqueries as Joins," in Chapter 2, some subqueries can be reformulated as logically equivalent joins. If your slow subquery is one of these, try writing it as a join to see if it performs better.
Test alternative forms of queries, but run them more than once. When testing alternative forms of a query (for example, a subquery versus an equivalent join), run it several times each way. If you run a query only once each of two different ways, you'll often find that the second query is faster just because information from the first query is still cached and need not actually be read from the disk. You should also try to run queries when the system load is relatively stable to avoid effects due to other activities on your system.
Avoid overuse of MySQL's automatic type conversion. MySQL will perform automatic type conversion, but if you can avoid conversions, you may get better performance. For example, if num_col is an integer column, each of these queries will return the same result:
SELECT * FROM mytbl WHERE num_col = 4; SELECT * FROM mytbl WHERE num_col = '4';But the second query involves a type conversion. The conversion operation itself involves a small performance penalty for converting the integer and string to double to perform the comparison. A more serious problem is that if num_col is indexed, a comparison that involves type conversion may prevent the index from being used.
The opposite kind of comparison (comparing a string column to a numeric value) also can prevent use of an index. Suppose that you write a query like this:
SELECT * FROM mytbl WHERE str_col = 4;In this case, an index on str_col cannot be used because there can be many different string values in str_col that are equal to 4 when converted to a number (for example, '4', '4.0', and '4th' ). The only way to know which values qualify is to read each one and perform the comparison.
Using EXPLAIN to Check Optimizer Operation
The EXPLAIN statement is useful for gaining insight into the execution plans that the optimizer generates for processing statements. In this section, I'll show two uses for EXPLAIN:- To see whether writing a query different ways affects whether an index can be used.
- To see the effect that adding indexes to a table has on the optimizer's ability to generate efficient execution plans.
Earlier, in "How the Optimizer Works," the point was made that the way you write an expression can determine whether the optimizer can use available indexes. Specifically, the discussion there used the example that of the three following logically equivalent WHERE clauses, only the third allows use of an index:
WHERE TO_DAYS(date_col) - TO_DAYS(CURDATE()) < cutoff WHERE TO_DAYS(date_col) < cutoff + TO_DAYS(CURDATE()) WHERE date_col < DATE_ADD(CURDATE(), INTERVAL cutoff DAY)EXPLAIN allows you to check whether one way of writing an expression is better than another. To see this, let's try using each of the WHERE clauses to search for expiration column values in the member table, using a cutoff value of 30 days. However, as originally created, the member table has no index on the expiration column. To allow the relationship to be seen between index use and how an expression is written, first index the expiration column:
mysql> ALTER TABLE member ADD INDEX (expiration);Then try EXPLAIN with each form of the expression to see what kind of execution plans the optimizer comes up with:
mysql> EXPLAIN SELECT * FROM MEMBER
-> WHERE TO_DAYS(expiration) - TO_DAYS(CURDATE()) < 30\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: MEMBER
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 102
Extra: Using where
mysql> EXPLAIN SELECT * FROM MEMBER
-> WHERE TO_DAYS(expiration) < 30 + TO_DAYS(CURDATE())\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: MEMBER
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 102
Extra: Using where
mysql> EXPLAIN SELECT * FROM MEMBER
-> WHERE expiration < DATE_ADD(CURDATE(), INTERVAL 30 DAY)\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: MEMBER
type: range
possible_keys: expiration
key: expiration
key_len: 4
ref: NULL
rows: 6
Extra: Using where
The results for the first two statements show that the index is not
used.
The type value indicates how values will be read from a
table. ALL means "all
records will be examined." That is, a full table scan will be
performed,
without benefit of an index. The NULL in each of the
key-related columns
also indicates that no index will be used.By contrast, the result for the third statement shows that the WHERE clause has been written such that the optimizer can use the index on the expiration column:
-
The type value indicates that it can use the index to
search
for a specific range of values (those less than the date given on
the right
side of the expression).
-
The possible_keys and key values show that the
index
on expiration is considered a candidate index and also is
the
index that actually would be used.
-
The rows value shows that the optimizer estimates that
it would
need to examine 6 rows to process the query. That's better than
the
value of 102 for the first two execution plans.
Support that we have two tables t1 and t2, each with 1,000 rows containing the values 1 to 1000. The query that we'll examine looks for those rows where corresponding values from the two tables are the same:
mysql> SELECT t1.i1, t2.i2 FROM t1, t2 WHERE t1.i1 = t2.i2; +------+------+ | i1 | i2 | +------+------+ | 1 | 1 | | 2 | 2 | | 3 | 3 | | 4 | 4 | | 5 | 5 | ...With no indexes on either of the tables, EXPLAIN produces this result:
mysql> EXPLAIN SELECT t1.i1, t2.i2 FROM t1, t2 WHERE t1.i1 = t2.i2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1000
Extra:
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: t2
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1000
Extra: Using where
Here, ALL in the type column indicates a full table scan
that examines
all rows. NULL in the possible_keys column indicates
that
no candidate indexes were found for speeding up the query. (The key,
key_len,
and ref columns all are NULL as well due to the lack
of a
suitable index.) Using where indicates that
information in
the WHERE clause is used to identify qualifying rows.These pieces of information tell us that the optimizer finds no useful information for executing the query more efficiently:
-
It will perform a full scan of t1.
-
For each row from t1, it will perform a full scan of t2,
using the information in the WHERE clause to identify
qualifying
rows.
To make this query more efficient, add an index on one of the joined columns and try the EXPLAIN statement again:
mysql> ALTER TABLE t2 ADD INDEX (i2);
mysql> EXPLAIN SELECT t1.i1, t2.i2 FROM t1, t2 WHERE t1.i1 = t2.i2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1000
Extra:
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: t2
type: ref
possible_keys: i2
key: i2
key_len: 5
ref: sampdb.t1.i1
rows: 10
Extra: Using where; Using index
This is an improvement. The output for t1 is unchanged
(indicating
that a full scan still will be done on the table), but the optimizer
can process t2 differently:-
type has changed from ALL to ref,
meaning that
a reference value (the value from t1) can be used to
perform an
index lookup to locate qualifying rows in t2.
-
The reference value is given in the ref field: sampdb.t1.i1.
-
The rows value has dropped from 1000 to 10, which shows
that
the optimizer believes that it will need to examine only 10 rows
in t2 for
each row in t1. (That is a somewhat pessimistic estimate.
In fact,
only one row in t2 will match each row from t1.
We'll
see a bit later how to help the optimizer improve this estimate.)
The total
estimated number of row combinations is 1,000 x 10 = 10,000.
That's
much better than the previous estimate of one million in the
absence of
any indexing.
mysql> ALTER TABLE t1 ADD INDEX (i1);
mysql> EXPLAIN SELECT t1.i1, t2.i2 FROM t1, t2 WHERE t1.i1 = t2.i2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: index
possible_keys: i1
key: i1
key_len: 5
ref: NULL
rows: 1000
Extra: Using index
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: t2
type: ref
possible_keys: i2
key: i2
key_len: 5
ref: sampdb.t1.i1
rows: 10
Extra: Using where; Using index
This output is similar to that for the previous EXPLAIN, but
adding
the index did make some difference in the output for t1. type
has
changed from NULL to index and Extra has
changed
from blank to Using index. These changes indicate
that, although
a full scan of the indexed values still would be done, the optimizer
now can
read them directly from the index without touching the data file at
all. You
will see this kind of result for a MyISAM table when the optimizer
knows that
it can get all the information it needs by consulting only the index
file.
You'll also see it for InnoDB and BDB tables when the optimizer can
use
information solely from the index without another seek to get the data
row.One further step we can take to help the optimizer make better cost estimates is to run ANALYZE TABLE. This causes the server to generate statistics about the distribution of key values. Analyzing the tables and running EXPLAIN again yields a better rows estimate:
mysql> ANALYZE TABLE t1, t2;
mysql> EXPLAIN SELECT t1.i1, t2.i2 FROM t1, t2 WHERE t1.i1 = t2.i2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: index
possible_keys: i1
key: i1
key_len: 5
ref: NULL
rows: 1000
Extra: Using index
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: t2
type: ref
possible_keys: i2
key: i2
key_len: 5
ref: sampdb.t1.i1
rows: 1
Extra: Using where; Using index
In this case, the optimizer now estimates that each value from t1
will
match only one row in t2.Overriding Optimization
It sounds odd, but there may be times when you'll want to defeat MySQL's optimization behavior:To override the optimizer's table join order. Use STRAIGHT_JOIN to force the optimizer to use tables in a particular order. If you do this, you should order the tables so that the first table is the one from which the smallest number of rows will be chosen. If you are not sure which table this is, put the table with the greatest number of rows first. In other words, try to order the tables to cause the most restrictive selection to come first. Queries perform better the earlier you can narrow the possible candidate rows. Make sure to try the query with and without STRAIGHT_JOIN. There might be some reason the optimizer isn't joining tables the way you think it should, and STRAIGHT_JOIN may not actually help.
Another possibility is to use the FORCE INDEX, USE INDEX, and IGNORE INDEX modifiers after a table name in the table list of a join to tell MySQL how to use indexes. This may be helpful in cases where the optimizer doesn't make the correct choice.
To empty a table with minimal side effects. When you need to empty a MyISAM table completely, it's fastest to have the server just drop the table and re-create it based on the description stored in its .frm file. To do this, use a TRUNCATE TABLE statement:
TRUNCATE TABLE tbl_name;The server's optimization of emptying a MyISAM table by re-creating it from scratch makes the operation extremely fast, because each row need not be deleted individually.
However, there are some side effects of TRUNCATE TABLE that may be undesirable under certain circumstances:
-
TRUNCATE TABLE does not necessarily produce an
accurate
count of the number of rows deleted. If you need this count, use a
DELETE statement
with no WHERE clause:
DELETE FROM tbl_name;
DELETE FROM tbl_name WHERE 1;Adding the WHERE clause forces MySQL to do a row-by-row deletion, because it must evaluate the condition for each row to determine whether to delete it. The statement executes much more slowly, but it preserves the current AUTO_INCREMENT sequence number.
Data Type Choices and Query Efficiency
This section provides some guidelines about choosing data types that can help queries run more quickly:Don't use longer columns when shorter ones will do. If you are using fixed-length CHAR columns, don't make them unnecessarily long. If the longest value you store in a column is 40 characters long, don't define it as CHAR(255); define it as CHAR(40). If you can use MEDIUMINT rather than BIGINT, your table will be smaller (less disk I/O), and values can be processed more quickly in computations. If the column is indexed, using shorter values gives you even more of a performance boost. Not only will the index speed up queries, shorter index values can be processed more quickly than longer values.
If you have a choice about row storage format, use one that is optimal for your storage engine. For MyISAM tables, use fixed-length columns rather than variable-length columns. For example, make all character columns CHAR rather than VARCHAR. The tradeoff is that your table will use more space, but if you can afford the extra space, fixed-length rows can be processed more quickly than variable-length rows. This is especially true for tables that are modified often and therefore more subject to fragmentation.
- With variable-length rows, you get more fragmentation of a table on which you perform many deletes or updates due to the differing sizes of the records. You'll need to run OPTIMIZE TABLE periodically to maintain performance. This is not an issue with fixed-length rows.
- Tables with fixed-length rows are easier to reconstruct if you have a table crash. The beginning of each record can be determined because they all are at positions that are multiples of the fixed record size, something that is not true with variable-length rows. This is not a performance issue with respect to query processing, but it can certainly speed up the table repair process.
- Fixed-length columns are faster but take more space. CHAR(n) columns always take n characters per value (even empty ones) because values are padded with trailing spaces when stored in the table. VARCHAR(n) columns take less space because only as many characters are allocated as necessary to store each value, plus one or two bytes per value to record the length. Thus, if you are choosing between CHAR and VARCHAR columns, the tradeoff is one of time versus space. If speed is your primary concern, use CHAR columns to get the performance benefits of fixed-length columns. If space is at a premium, use VARCHAR columns. As a rule of thumb, you can assume that fixed-length rows will improve performance even though more space is used. But for an especially critical application, you may wish to implement a table both ways and run some tests to determine which alternative actually is better for your particular application.
- Sometimes you cannot use a fixed-length type, even if you want to. There is no fixed-length type for strings longer than 255 characters, for example.
For InnoDB tables, the internal row storage format does not treat fixed-length and variable-length columns differently (all rows use a header containing pointers to the column values), so using fixed-length CHAR columns is not in itself intrinsically simpler than using variable-length VARCHAR columns. Consequently, the primary performance factor is the amount of storage used for rows. Because CHAR on average takes more space than VARCHAR, it's preferable to use VARCHAR to minimize the amount of storage and disk I/O needed to process rows.
For BDB tables, it usually doesn't make much difference whether you use fixed-length or variable-length columns. You can try a table both ways and run some empirical tests to check whether there's a significant difference for your particular system.
Define columns to be NOT NULL. This gives you faster processing and requires less storage. It will also simplify queries sometimes because you don't need to check for NULL as a special case.
Consider using ENUM columns. If you have a string column that has low cardinality (contains only a limited number of distinct values), consider converting it to an ENUM column. ENUM values can be processed quickly because they are represented as numeric values internally.
Use PROCEDURE ANALYSE(). Run PROCEDURE ANALYSE() to see what it tells you about the columns in your table:
SELECT * FROM tbl_name PROCEDURE ANALYSE(); SELECT * FROM tbl_name PROCEDURE ANALYSE(16,256);One column of the output will be a suggestion for the optimal data type for each of the columns in your table. The second example tells PROCEDURE ANALYSE() not to suggest ENUM types that contain more than 16 values or that take more than 256 bytes (you can change the values as you like). Without such restrictions, the output may be very long; ENUM definitions are often difficult to read.
Based on the output from PROCEDURE ANALYSE(), you may find that your table can be changed to take advantage of a more efficient type. Use ALTER TABLE if you decide to change a column's type.
Use OPTIMIZE TABLE for tables that are subject to fragmentation. Tables that are modified a great deal, particularly those that contain variable-length columns, are subject to fragmentation. Fragmentation is bad because it leads to unused space in the disk blocks used to store your table. Over time, you must read more blocks to get the valid rows, and performance is reduced. This is true for any table with variable-length rows, but is particularly acute for BLOB or TEXT columns because they can vary so much in size. Use of OPTIMIZE TABLE on a regular basis helps keep performance on the table from degrading.
OPTIMIZE TABLE can be used with MyISAM and BDB tables, but defragments only MyISAM tables. A defragmentation method that works for any storage engine is to dump the table with mysqldump, and then drop and re-create it using the dump file:
% mysqldump --opt db_name tbl_name > dump.sql % mysql db_name < dump.sqlPack data into a BLOB or TEXT column. Using a BLOB or TEXT column to store data that you pack and unpack in your application may allow you to get everything with a single retrieval operation rather than with several. This can also be helpful for data values that are not easy to represent in a standard table structure or that change over time. In the discussion of the ALTER TABLE statement in Chapter 2, one of the examples dealt with a table being used to hold results from the fields in a Web-based questionnaire. That example discussed how you could use ALTER TABLE to add columns to the table whenever you add questions to the questionnaire.
Another way to approach this problem is to have the application program that processes the Web form pack the data into some kind of data structure, and then insert it into a single BLOB or TEXT column. For example, you could represent the questionnaire responses using XML and store the XML string in a TEXT column. This adds application overhead on the client side for encoding the data (and decoding it later when you retrieve records from the table), but simplifies the table structure, and eliminates the need to change the table structure when you change your questionnaire.
On the other hand, BLOB and TEXT values can cause their own problems, especially if you do a lot of DELETE or UPDATE operations. Deleting such values can leave large holes in the table that will be filled in later with a record or records of probably different sizes. (The preceding discussion of OPTIMIZE TABLE suggests how you might deal with this.)
Use a synthetic index. Synthetic index columns can sometimes be helpful. One method is to create a hash value based on other columns and store it in a separate column. Then you can find rows by searching for hash values. However, note that this technique is good only for exact-match queries. (Hash values are useless for range searches with operators such as < or >=.) Hash values can be generated by using the MD5() function. Other options are to use SHA1() or CRC32(). Or you can compute your own hash values using logic within your application. Remember that a numeric hash value can be stored very efficiently. Also, if the hash algorithm might produce string values that have trailing spaces, do not store them in a CHAR or VARCHAR column, which are subject to trailing space removal.
A synthetic hash index can be particularly useful with BLOB and TEXT columns. It can be much quicker to find BLOB values using a hash as an identifier value than by searching the BLOB column itself.
Avoid retrieving large BLOB or TEXT values unless you must. For example, a SELECT * query isn't a good idea unless you're sure the WHERE clause is going to restrict the results to just the rows you want. Otherwise, you may be pulling potentially very large values over the network for no purpose. This is another case where BLOB or TEXT identifier information stored in a synthetic index column can be useful. You can search that column to determine the row or rows you want and then retrieve the BLOB or TEXT values from the qualifying rows.
Segregate BLOB or TEXT columns into a separate table. Under some circumstances, it may make sense to move these columns out of a table into a secondary table, if that allows you to convert the table to fixed-length row format for the remaining columns. This will reduce fragmentation in the primary table and allow you to take advantage of the performance benefits of having fixed-length rows. It also allows you to run SELECT * queries on the primary table without pulling large BLOB or TEXT values over the network.
Loading Data Efficiently
Most of the time you'll probably be concerned about optimizing SELECT queries, because they are the most common type of query and because it's not always straightforward to figure out how to optimize them. By comparison, loading data into your database is straightforward. Nevertheless, there are strategies you can use to improve the efficiency of data-loading operations. The basic principles are these:- Bulk loading is more efficient than single-row loading because the key cache need not be flushed after each record is loaded; it can be flushed at the end of the batch of records. The more you can reduce key cache flushing, the faster data loading will be.
- Loading is faster when a table has no indexes than when it is indexed. If there are indexes, not only must the record be added to the data file, but also each index must be modified to reflect the addition of the new record.
- Shorter SQL statements are faster than longer statements because they involve less parsing on the part of the server and because they can be sent over the network from the client to the server more quickly.
-
LOAD DATA (all forms) is more efficient than INSERT
because
it loads rows in bulk. The server must parse and interpret only
one statement,
not several. Also, the index needs flushing only after all rows
have been
processed, rather than after each row.
-
LOAD DATA is more efficient without LOCAL
than
with it. Without LOCAL, the file must be located on the
server
and you must have the FILE privilege, but the server can
read
the file directly from disk. With LOAD DATA LOCAL,
the client reads the file and sends it over the network to the
server,
which is slower.
-
If you must use INSERT, try to use the form that allows
multiple
rows to be specified in a single statement:
INSERT INTO tbl_name VALUES(...),(...),... ;The more rows you can specify in the statement, the better. This reduces the total number of statements you need and minimizes the amount of index flushing. This might seem to contradict the earlier remark that shorter statements can be processed faster than longer statements. But there is no contradiction. The principles here are that a single INSERT statement that inserts multiple rows is shorter overall than an equivalent set of individual single-row INSERT statements, and the multiple-row statement can be processed on the server with much less index flushing.
If you use mysqldump to generate database backup files, it generates multiple-row INSERT statements by default as of MySQL 4.1: The --opt (optimize) option is enabled, which turns on the --extended-insert option that produces multiple-row INSERT statements, as well as some other options that allow the dump file to be processed more efficiently when it is reloaded. Before MySQL 4.1, you can specify the --opt or --extended-insert option explicitly.
Avoid using the --complete-insert option with mysqldump; the resulting INSERT statements will be for single rows and will be longer and require more parsing than will multiple-row statements.
START TRANSACTION; INSERT INTO tbl_name ... ; INSERT INTO tbl_name ... ; INSERT INTO tbl_name ... ; COMMIT;For non-transactional storage engines, obtain a write lock on the table and issue the INSERT statements while the table is locked:
LOCK TABLES tbl_name WRITE; INSERT INTO tbl_name ... ; INSERT INTO tbl_name ... ; INSERT INTO tbl_name ... ; UNLOCK TABLES;Either way, you obtain the same benefit: The index is flushed once after all the statements have been executed rather than once per INSERT statement. The latter is what happens in autocommit mode or if the table has not been locked.
For a replication slave server, you might want to use --delay-key-write=ALL to delay index flushing for all MyISAM tables, regardless of how they were created originally on the master server.
To drop and rebuild indexes, use DROP INDEX and CREATE INDEX, or the index-related forms of ALTER TABLE. To deactivate and reactivate indexes, you have two choices:
-
You can use the DISABLE KEYS and ENABLE
KEYS forms
of ALTER TABLE:
ALTER TABLE tbl_name DISABLE KEYS; ALTER TABLE tbl_name ENABLE KEYS;These statements turn off and on updating of any non-unique indexes in the table.
The DISABLE KEYS and ENABLE KEYS clauses for ALTER TABLE are the preferred method for index deactivation and activation, because the server does the work. (Note that if you're using a LOAD DATA statement to load data into an empty MyISAM table, the server performs this optimization automatically.)
% myisamchk --keys-used=0 tbl_nameAfter loading the table with data, reactivate the indexes:
% myisamchk --recover --quick --keys-used=n tbl_namen is interpreted as a bitmask indicating which indexes to enable. Bit 0 (the first bit) corresponds to index 1. For example, if a table has three indexes, the value of n should be 7 (111 binary). You can determine index numbers with the --description option:
% myisamchk --description tbl_nameThe preceding data-loading principles also apply to mixed-query environments involving clients performing different kinds of operations. For example, you generally should avoid long-running SELECT queries on tables that are changed (written to) frequently. This causes a lot of contention and poor performance for the writers. A possible way around this, if your writes are mostly INSERT operations, is to add new records to an auxiliary table and then add those records to the main table periodically. This is not a viable strategy if you need to be able to access new records immediately, but if you can afford to leave them inaccessible for a short time, use of the auxiliary table will help you two ways. First, it reduces contention with SELECT queries that are taking place on the main table, so they execute more quickly. Second, it takes less time overall to load a batch of records from the auxiliary table into the main table than it would to load the records individually; the key cache need be flushed only at the end of each batch, rather than after each individual row.
One application for this strategy is when you're logging Web page accesses from your Web server into a MySQL database. In this case, it may not be a high priority to make sure that the entries get into the main table right away.
If you're using mixed INSERT and SELECT statements with a MyISAM table, you might be able to take advantage of concurrent inserts. This feature allows the inserts to take place at the same time as retrievals without the use of an auxiliary table. See "Using Concurrent Inserts" for details.
Scheduling and Locking Issues
The previous sections focus primarily on making individual queries faster. MySQL also allows you to affect the scheduling priorities of statements, which may allow queries arriving from several clients to cooperate better so that individual clients aren't locked out for a long time. Changing the priorities can also ensure that particular kinds of queries are processed more quickly. This section looks at MySQL's default scheduling policy and the options that are available to you for influencing this policy. It also describes the use of concurrent inserts and the effect that storage engine locking levels have on concurrency among clients. For the purposes of this discussion, a client performing a retrieval (a SELECT) is a reader. A client performing an operation that modifies a table (DELETE, INSERT, REPLACE, or UPDATE) is a writer.MySQL's default scheduling policy can be summarized like this:
- Writes have higher priority than reads.
- Writes to a table must occur one at a time, and write requests are processed in the order in which they arrive.
- Multiple reads from a table can be processed simultaneously.
A client performing a write to a table must have a lock for exclusive table access. The table is in an inconsistent state while the operation is in progress because the data record is being deleted, added, or changed, and any indexes on the table may need to be updated to match. Allowing other clients to access the table while the table is in flux would cause problems. It's clearly a bad thing to allow two clients to write to the table at the same time because that would quickly corrupt the table into an unusable mess. But it's not good to allow a client to read from an in-flux table, either, because the table might be changing at the location being read, and the results would be inaccurate.
A client performing a read from a table must have a lock to prevent other clients from writing to the table and changing it during the read. The lock need not be for exclusive access, however. Reading doesn't change the table, so there is no reason one reader should prevent another from accessing the table. Therefore, a read lock allows other clients to read the table at the same time.
MySQL provides several statement modifiers that allow you to influence its scheduling policy:
- The LOW_PRIORITY keyword applies to DELETE, INSERT, LOAD DATA, REPLACE, and UPDATE statements.
- The HIGH_PRIORITY keyword applies to SELECT and INSERT statements.
- The DELAYED keyword applies to INSERT and REPLACE statements.
Changing Statement Scheduling Priorities
The LOW_PRIORITY keyword affects execution scheduling for DELETE, INSERT, LOAD DATA, REPLACE, and UPDATE statements. Normally, if a write operation for a table arrives while the table is being read, the writer blocks until the reader is done. (Once a query has begun it will not be interrupted, so the reader is allowed to finish.) If another read request arrives while the writer is waiting, the reader blocks, too, because the default scheduling policy is that writers have higher priority than readers. When the first reader finishes, the writer proceeds, and when the writer finishes, the second reader proceeds.If the write request is a LOW_PRIORITY request, the write is not considered to have a higher priority than reads. In this case, if a second read request arrives while the writer is waiting, the second reader is allowed to slip in ahead of the writer. Only when there are no more readers is the writer allowed to proceed. One implication of this scheduling modification is that, theoretically, it's possible for LOW_PRIORITY writes to be blocked forever. If additional read requests keep arriving while previous ones are still in progress, the new requests are allowed to get in ahead of the LOW_PRIORITY write.
The HIGH_PRIORITY keyword for SELECT queries is similar. It allows a SELECT to slip in ahead of a waiting write, even if the write normally has higher priority. Another effect is that a high-priority SELECT will execute ahead of normal SELECT statements, because those will block for the write.
If you want all statements that support the LOW_PRIORITY option to be treated as having low priority by default, start the server with the --low-priority-updates option. The effect of this option can be canceled for individual INSERT statements by using INSERT HIGH_PRIORITY to elevate them to the normal write priority.
Using Delayed Inserts
The DELAYED modifier applies to INSERT and REPLACE statements. When a DELAYED insert request arrives for a table, the server puts the rows in a queue and returns a status to the client immediately so that the client can proceed even before the rows have been inserted. If readers are reading from the table, the rows in the queue are held until there are no readers. Then the server begins inserting the rows in the delayed-row queue. Every now and then, the server checks whether any new read requests have arrived and are waiting. If so, the delayed-row queue is suspended and the readers are allowed to proceed. When there are no readers left, the server begins inserting delayed rows again. This process continues until the queue is empty.LOW_PRIORITY and DELAYED are similar in the sense that both allow row insertion to be deferred, but they are quite different in how they affect client operation. LOW_ PRIORITY forces the client to wait until the rows can be inserted. DELAYED allows the client to continue and the server buffers the rows in memory until it has time to process them.
INSERT DELAYED is useful if other clients may be running lengthy SELECT statements and you don't want to block waiting for completion of the insertion. The client issuing the INSERT DELAYED can proceed more quickly because the server simply queues the row to be inserted.
You should be aware of certain other differences between normal INSERT and INSERT DELAYED behavior, however. The client gets back an error if the INSERT DELAYED statement contains a syntax error, but other information that would normally be available is not. For example, you can't rely on getting the AUTO_INCREMENT value when the statement returns. Also, you won't get a count for the number of duplicates on unique indexes. This happens because the insert operation returns a status before the operation actually has been completed. Another implication is that because rows from INSERT DELAYED statements are queued in memory, the rows are lost if the server crashes or is killed with kill -9. (This doesn't happen a normal kill -TERM kill; in that case, the server inserts the rows before exiting.)
Using Concurrent Inserts
The MyISAM storage engine allows an exception to the general principle that readers block writers. This occurs under the condition that a MyISAM table has no holes in the middle such as can result from deleting or updating rows. When the table has no holes, any INSERT statements must necessarily add rows at the end rather than in the middle. Under such circumstances, MySQL allows clients to add rows to the table even while other clients are reading from it. These are known as "concurrent inserts" because they take place at the same time as retrievals without being blocked.If you want to use concurrent inserts, note the following:
- Do not use the LOW_PRIORITY modifier with your INSERT statements. It causes INSERT always to block for readers and thus prevents concurrent inserts from being performed.
- Readers that need to lock the table explicitly but still want to allow concurrent inserts should use LOCK TABLES ... READ LOCAL rather than LOCK TABLES ... READ. The LOCAL keyword acquires a lock that allows concurrent inserts to proceed, because it applies only to existing rows in the table and does not block new rows from being added to the end.
- LOAD DATA operations should use the CONCURRENT modifier to allow SELECT statements for the table to take place at the same time.
- A MyISAM table that has holes in the middle cannot be used for concurrent inserts. However, you can defragment the table with the OPTIMIZE TABLE statement.
Locking Levels and Concurrency
The scheduling modifiers discussed in the preceding sections allow you to influence the default scheduling policy. For the most part, these modifiers were introduced to deal with issues that arise from the use of table-level locks, which is what the MyISAM and MEMORY storage engines use to manage table contention.The BDB and InnoDB storage engines implement locking at different levels and thus have differing performance characteristics in terms of contention management. The BDB engine uses page-level locks. The InnoDB engine uses row-level locks, but only as necessary. (In many cases, such as when only reads are done, InnoDB may use no locks at all.)
The locking level used by a storage engine has a significant effect on concurrency among clients. Suppose that two clients each want to update a row in a given table. To perform the update, each client requires a write lock. For a MyISAM table, the engine will acquire a table lock for the first client, which causes the second client to block until the first one has finished. With a BDB table, greater concurrency can be achieved: Both updates can proceed simultaneously unless both rows are located within the same page. With an InnoDB table, concurrency is even higher; both updates can happen at the same time as long as both clients aren't updating the same row.
The general principle is that table locking at a finer level allows better concurrency, because more clients can be using a table at the same time if they use different parts of it. The practical implication is that different storage engines will be better suited for different statement mixes:
- MyISAM is extremely fast for retrievals. However, the use of table-level locks can be a problem in environments with mixed retrievals and updates, especially if the retrievals tend to be long-running. Under these conditions, updates may need to wait a long time before they can proceed.
- BDB and InnoDB tables can provide better performance when there are many updates. Because locking is done at the page or row level rather than at the table level, the extent of the table that is locked is smaller. This reduces lock contention and improves concurrency.
Optimization for Administrators
The previous sections describe optimizations that can be performed by unprivileged MySQL users. Administrators who have control of the MySQL server or the machine on which it runs can perform additional optimizations. For example, some server parameters pertain to query processing and may be tuned, and certain hardware configuration factors have a direct effect on query processing speed. In many cases, these optimizations improve the performance of the server as a whole, and thus have a beneficial effect for all MySQL users.In general, you should keep the following principles in mind when performing administrative optimizations:
- Accessing data in memory is faster than accessing data from disk.
- Keeping data in memory as long as possible reduces disk activity.
- Retaining information from an index is more important than retaining contents of data records.
Increase the size of the server's caches. The server has many parameters (system variables) that you can change to affect its operation. Several of these directly affect the speed of query processing. The most important parameters you can change are the sizes of the table cache and the caches used by the storage engines to buffer information for indexing operations. If you have memory available, allocating it to the server's caches allows information to be held in memory longer and reduces disk activity. This is good, because it's much faster to access information from memory than to read it from disk.
-
When the server opens table files, it tries to keep them open so
as to
minimize the number of file-opening operations. To do this, it
maintains
information about open files in the table cache. The table_cache
system
variable controls the size of this cache. If the server accesses
lots of
tables, the table cache fills up and the server closes tables that
haven't
been used for a while to make room for opening new tables. You can
assess
how effective the table cache is by checking the Opened_tables
status
indicator:
SHOW STATUS LIKE 'Opened_tables';Opened_tables indicates the number of times a table had to be opened because it wasn't already open. (This value is also displayed as the Opens value in the output of the mysqladmin status command.) If the number remains stable or increases slowly, it's probably set to about the right value. If the number grows quickly, it means the cache is too small and that tables often have to be closed to make room to open other tables. If you have file descriptors available, increasing the table cache size will reduce the number of table opening operations.
- Change one parameter at a time. Otherwise, you're varying multiple independent variables and it becomes more difficult to assess the effect of each change.
- Increase system variable values incrementally. If you increase a variable by a huge amount on the theory that more is always better, you may run your system out of resources, causing it to thrash or slow to a crawl because you've set the value too high.
- Rather than experimenting with parameter tuning on your production MySQL server, it might be prudent to set up a separate test server.
- To get an idea of the kinds of parameter variables that are likely to be appropriate for your system, take a look at the my-small.cnf, my-medium.cnf, my-large.cnf, and my-huge.cnf option files included with MySQL distributions. (On Unix, you can find them under the support-files directory in source distributions and under the share directory in binary distributions. On Windows, they are located in the base installation directory, and the filename suffix might be .ini.) These files will give you some idea of which parameters are best to change for servers that receive different levels of use, and also some representative values to use for those parameters.
Disable storage engines that you don't need. The server won't allocate any memory for disabled engines, allowing you to devote it to other uses. Most storage engines can be excluded from the server binary at configuration time if you build MySQL from source. For those engines that are included in the server, many can be disabled at runtime with the appropriate startup options. See "Selecting Storage Engines," in Chapter 11, "General MySQL Administration" for details.
Keep grant table permissions simple. Although the server caches grant table contents in memory, if you have any rows in the tables_priv or columns_priv tables, the server must check table- and column-level privileges for every query. If those tables are empty, the server can optimize its privilege checking to skip those levels.
If you build MySQL from source, configure it to use static libraries rather than shared libraries. Dynamic binaries that use shared libraries save on disk space, but static binaries are faster. However, some systems require dynamic linking if you use the user-defined function (UDF) mechanism. On such systems, static binaries will not work.
Using MyISAM Key Caches
When MySQL executes a statement that uses indexes from MyISAM tables, it uses a key cache to hold index values. The cache allows disk I/O to be reduced: If key values needed from a table are found in the cache, they need not be read from disk again. Unfortunately, the key cache is a finite resource and it is shared among all MyISAM tables by default. If key values are not found in the cache and the cache is full, contention results: Some values currently in the cache must be discarded to make room for new values. The next time the discarded values are needed, they must be read from disk again.If you have an especially heavily used MyISAM table, it would be nice to ensure that its keys remain in memory, but contention in the cache works against this. Contention can arise either when keys need to be read from the same table, or from other tables. You might avoid same-table contention by making the key cache large enough to hold all of a given table's indexes completely, but keys from other tables still could contend for space in the cache.
MySQL 4.1 and up offers a solution to this problem because it supports setting up multiple key caches and allows a table's indexes to be assigned to and preloaded into a given cache. This can be useful if you have a table that sees especially heavy use and you have sufficient memory to load its indexes into the cache. This capability enables you to avoid both same-table and other-table contention: Create a cache that is large enough to hold a table's indexes completely and devote the cache exclusively to the use of that table. No disk I/O is necessary after the keys have been loaded into the cache. Also, key values will never need to be discarded from the cache and key lookups for the table can be done in memory.
The following example shows how to set up a key cache for the member table in the sampdb database, using a cache with a name of member_cache and a size of 1MB. You must have the SUPER privilege to carry out these instructions.
-
Set up a separate key cache large enough to hold the indexes from
the
table:
-
Assign the table to the key cache:
-
Preload the table's indexes into its key cache:
mysql> SET GLOBAL member_cache.key_buffer_size = 1024*1024;
mysql> CACHE INDEX member IN member_cache; +---------------+--------------------+----------+----------+ | Table | Op | Msg_type | Msg_text | +---------------+--------------------+----------+----------+ | sampdb.member | assign_to_keycache | status | OK | +---------------+--------------------+----------+----------+
mysql> LOAD INDEX INTO CACHE member; +---------------+--------------+----------+----------+ | Table | Op | Msg_type | Msg_text | +---------------+--------------+----------+----------+ | sampdb.member | preload_keys | status | OK | +---------------+--------------+----------+----------+
Using the Query Cache
The MySQL server can use a query cache to speed up processing of SELECT statements that are executed repeatedly. The resulting performance improvement often is dramatic. The query cache works as follows:- The first time a given SELECT statement is executed, the server remembers the text of the query and the results that it returns.
- The next time the server sees that statement, it doesn't bother to execute it again. Instead, the server pulls the result directly from the query cache and returns it to the client.
- Query caching is based on the literal text of query strings as they are received by the server. Queries are considered the same if the text of the queries is exactly the same. Queries are considered different if they differ in lettercase or come from clients that are using different character sets or communication protocols. They also are considered different if they are otherwise identical but do not actually refer to the same tables (for example, if they refer to identically named tables in different databases).
- When a table is updated, any cached queries that refer to it become invalid and are discarded. This prevents the server from returning out-of-date results.
To determine whether a server supports the query cache, check the value of the have_query_cache system variable:
mysql> SHOW VARIABLES LIKE 'have_query_cache'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | have_query_cache | YES | +------------------+-------+For servers that do include query cache support, cache operation is based on the values of three system variables:
- query_cache_type determines the operating mode of the query cache. The following table shows the possible mode values:
- query_cache_size determines the amount of memory to allocate for the cache, in bytes.
- query_cache_limit sets the maximum result set size that will be cached; query results larger than this value are never cached.
|
Mode |
Meaning |
|
0 |
Don't cache query results or retrieve cached results. |
|
1 |
Cache queries except those that begin with SELECT
SQL_NO_CACHE. |
|
2 |
Cache on demand only those queries that begin with SELECT
SQL_CACHE. |
[mysqld] query_cache_type=1 query_cache_size=16MThe amount of memory indicated by query_cache_size is allocated even if query_cache_type is zero. To avoid wasting memory, don't set the size greater than zero unless you plan to enable the cache. Also, a size of zero effectively disables the cache even if query_cache_type is non-zero.
Individual clients begin with query caching behavior in the state indicated by the server's default caching mode. A client can change the default caching mode for its queries by using this statement:
SET query_cache_type = val;val can be 0, 1, or 2, which have the same meanings as when setting the query_cache_type variable at server startup. In a SET statement, the symbolic values OFF, ON, and DEMAND are synonyms for 0, 1, and 2.
A client also can control caching of individual queries by adding a modifier following the SELECT keyword. SELECT SQL_CACHE causes the query result to be cached if the cache mode is ON or DEMAND. SELECT SQL_NO_CACHE causes the result not to be cached.
Suppression of caching can be useful for queries that retrieve information from a constantly changing table. In that case, the cache is unlikely to be of much use. Suppose that you're logging Web server requests to a table in MySQL, and also that you periodically run a set of summary queries on the table. For a reasonably busy Web server, new rows will be inserted into the table frequently and thus any query results cached for the table become invalidated quickly. The implication is that although you might issue the summary queries repeatedly, it's unlikely that the query cache will be of any value for them. Under such circumstances, it makes sense to issue the queries using the SQL_NO_CACHE modifier to tell the server not to bother caching their results.
Hardware Issues
The earlier part of this chapter discusses techniques that help improve your server's performance regardless of your hardware configuration. You can of course get better hardware to make your server run faster. But not all hardware-related changes are equally valuable. When assessing what kinds of hardware improvements you might make, the most important principles are the same as those that apply to server parameter tuning: Put as much information in fast storage as possible, and keep it there as long as possible.Several aspects of your hardware configuration can be modified to improve server performance:
Install more memory into your machine. This enables you to configure larger values for the server's cache and buffer sizes, which allows it to keep data in memory longer and with less need to fetch information from disk.
Reconfigure your system to remove all disk swap devices if you have enough RAM to do all swapping into a memory filesystem. Otherwise, some systems will continue to swap to disk even if you have sufficient RAM for swapping.
Add faster disks to improve I/O latency. Seek time is typically the primary determinant of performance here. It's slow to move the heads laterally; after the heads have been positioned, reading blocks off the track is fast by comparison. However, if you have a choice between adding more memory and getting faster disks, add more memory. Memory is always faster than your disks, and adding memory allows you to use larger caches, which reduces disk activity.
Take advantage of parallelism by redistributing disk activity across physical devices. If you can split reading or writing across multiple physical devices, it will be quicker than reading and writing everything from the same device. For example, if you store databases on one device and logs on another, writing to both devices at once it will be faster than if databases and logs share the same device. Note that using different partitions on the same physical device doesn't count as parallelism. That won't help because they'll still contend for the same physical resource (disk heads). The procedure for moving logs and databases is described in Chapter 10, "The MySQL Data Directory."
Before you relocate data to a different device, make sure that you understand your system's load characteristics. If there's some other major activity already taking place on a particular physical device, putting a database there may actually make performance worse. For example, you may not realize any overall benefit if you process a lot of Web traffic and move a database onto the device where your Web server document tree is located.
Use of RAID devices can give you some advantages of parallelism as well.
Use multi-processor hardware. For a multi-threaded application like the MySQL server, multi-processor hardware can execute multiple threads at the same time. Source: http://www.informit.com




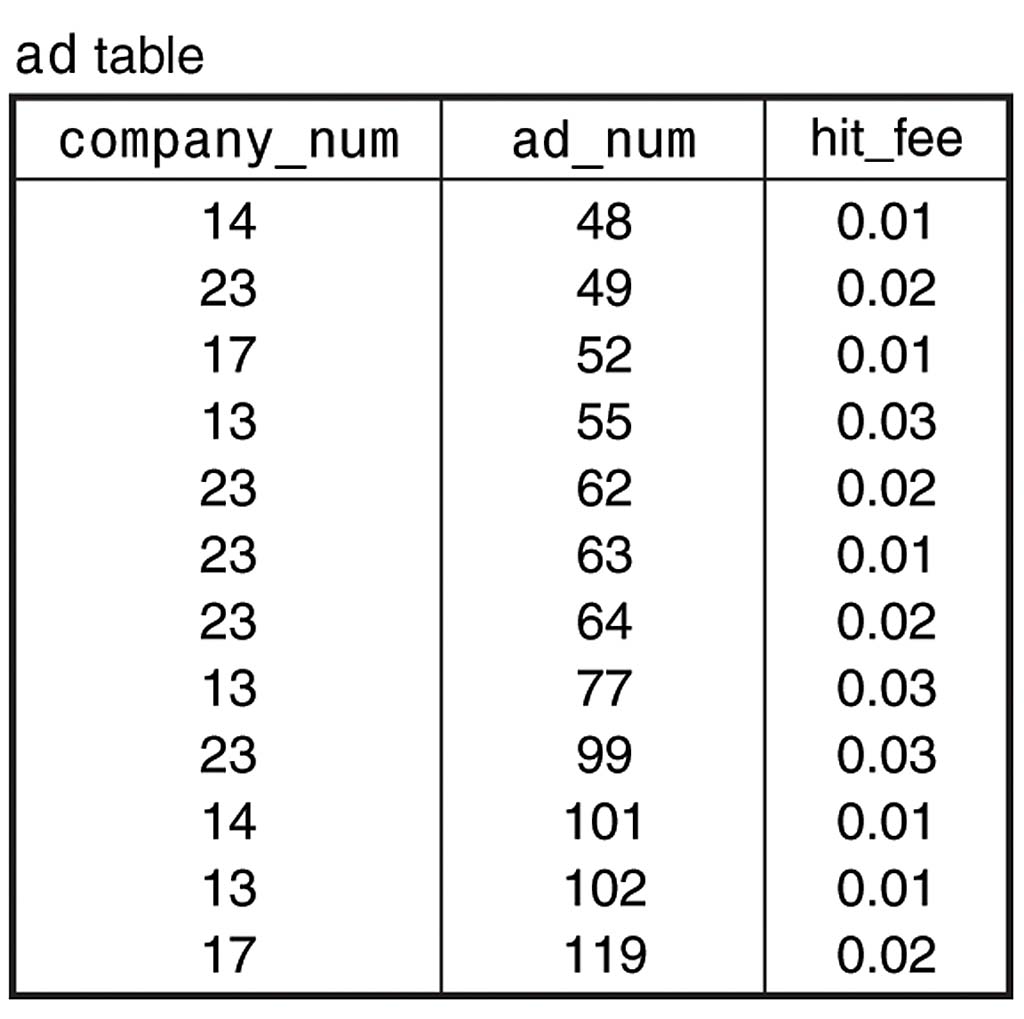{kind=link}
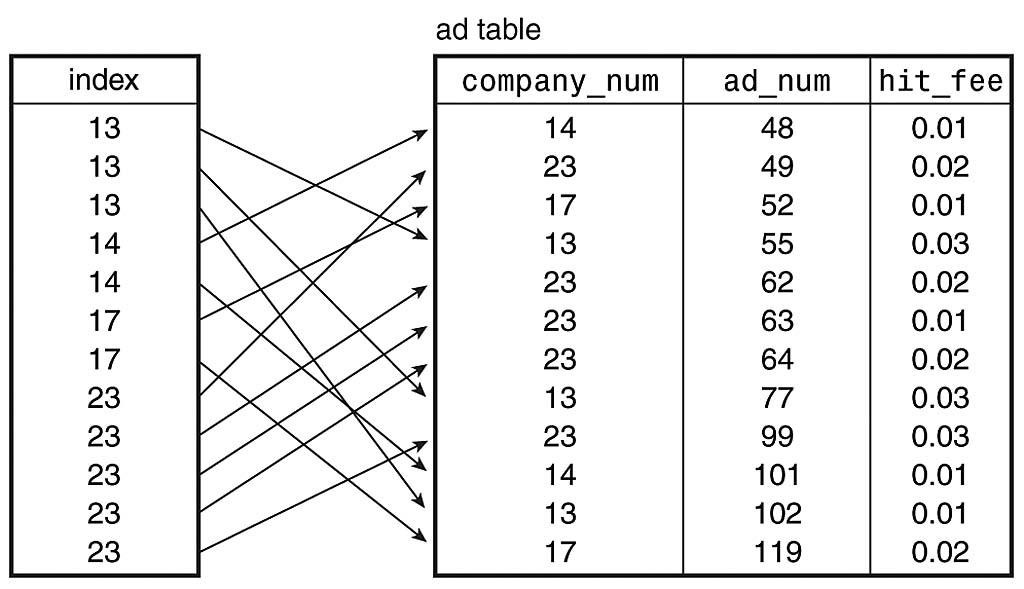{kind=link}