Embedding models may be used for Retrieval Augmented Generation (RAG) and create fixed-length vector representations of text, focusing on semantic meaning for tasks like similarity comparison.
LLMs (Large Language Models) are generative AI models that can understand and produce general language tasks and have more flexibility of input/output formats
A. Embedding Models
1. Static Embeddings
Static embeddings generate fixed vector representations for each word in the vocabulary, regardless of the context or order in which the word appears. While contextual embeddings, produces different vectors for the same word based on its context within a sentence.
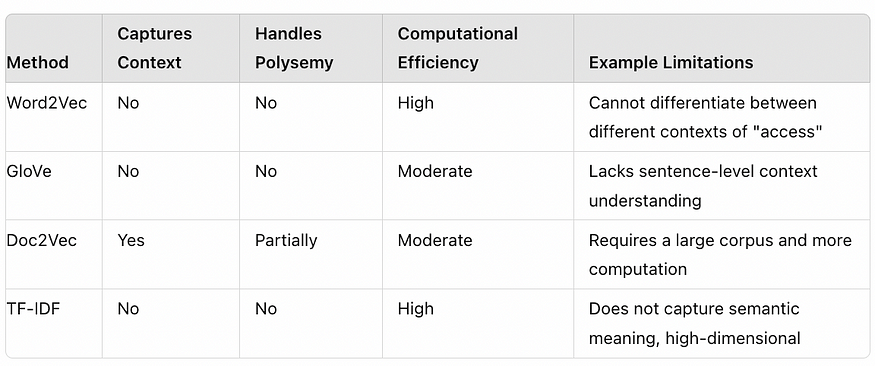
With Word2Vec, GloVE, Doc2Vec (Dense vector based) and TF-IDF (keyword /Sparse vector based), the vectors for “access” and “account” in both the query and the log will be similar, returning relevant results based on cosine similarity
Limitations
- Polysemy Issue: Words with multiple meanings (e.g., “bank”) have the same vector regardless of context [river bank, financial bank]
- Context Insensitivity once embeddings are generated: Cannot differentiate between “access denied” due to various reasons (e.g., incorrect password, account lockout).
Comparison Summary
2. Contextual Embeddings
BERT, RoBERTa, SBERT, ColBERT, MPNet
- Bidirectional: Captures context from both directions within a sentence, leading to a deep understanding of the entire sentence.
- Focused Context: Primarily designed for understanding the context within relatively short spans of text (e.g., sentences or paragraphs).
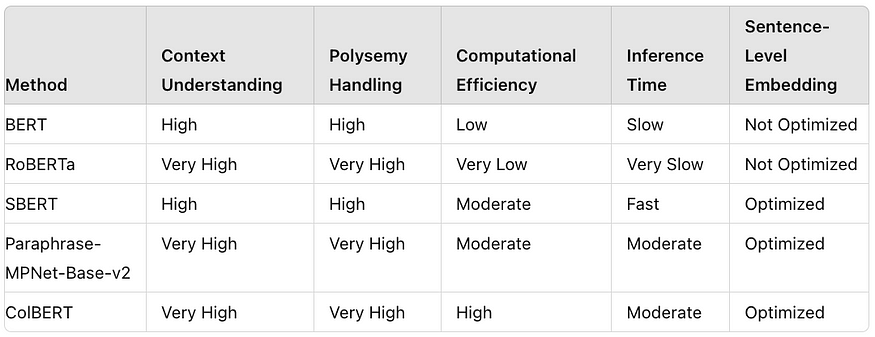
BERT, RoBERTa , all-MiniLM-L6-v2 or SBERT (Masked language Model), Paraphrase-MPNet-Base-v2 (Permutated Language Model) embeddings capture the context and understand that “can’t access my account” is related to “access denied” and “cannot login” because they all involve issues with account access. Good choice for retrieval step
ColBERT (Contextualized Late Interaction over BERT) is a retrieval model that uses BM25 for initial document retrieval and then applies BERT-based contextual embeddings for detailed re-ranking, optimizing both efficiency and contextual relevance in information retrieval tasks.
Limitations
- Context Limitation: Masked and Permuted Language Model is good at understanding context within a given text span (like a sentence or paragraph), but it doesn’t have the capacity to generate text or handle tasks beyond understanding and retrieving relevant documents.
Comparison Summary
3. GPT-Based Embeddings
- Unidirectional: Captures context from the left side only, building understanding sequentially as it generates text.
- Broad Context: Can maintain coherence over longer text sequences, making them effective for generating extended passages of text.
OpenAI’s text-embedding-3 -large
google-gecko-text-embedding
amazon-titan
GTR-T5 is Google’s open-source embedding model for semantic search using the T5 LLM as a base
E5 (v1 and v2) is the newest embedding model from Microsoft.
Generative-based embeddings: Good for the generation step of RAG. They recognize that “cannot login after password reset” and “login failed after updating security settings” are related to “can’t access my account.” They can also generate relevant responses based on deeper understanding and broader context.
Limitations:
- Generative models like GPT can be more resource-intensive than purely contextual models like BERT.
B. Large Language Models (LLMs)
Combine the retrieved information (embedding) for response generation by LLM models
Open AI GPT 4o
Google Gemini Pro
Anthropic Claude3.5 Sonner
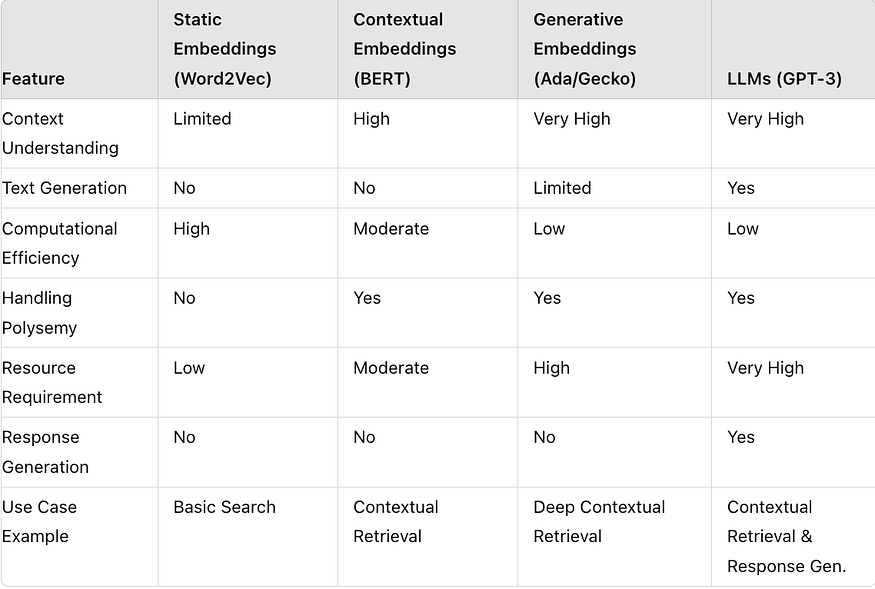
Metrics for choosing Embeddings
- MTEB retrieval score (Huggingface Massive Text Embedding Benchmark)
- ex: Google gecko > Open AI text embedding 3 large > miniLM (Sbert)
- GTR-T5 (google’s open source) is good MTEB retrieval score but slow
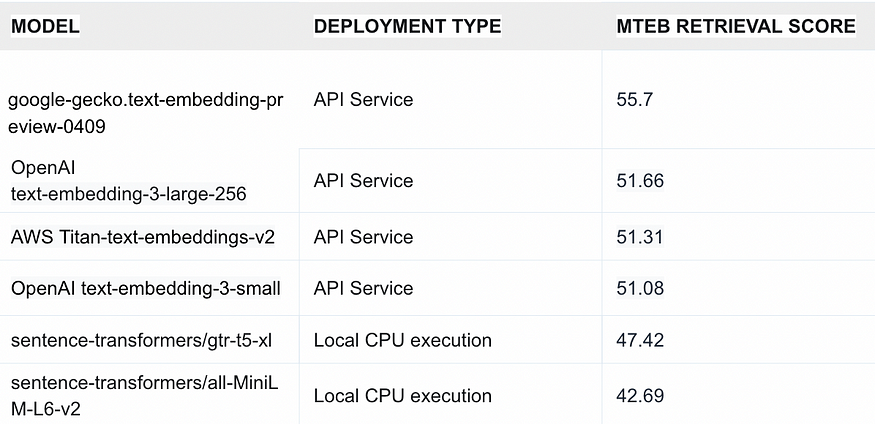
- all-miniLM (Sbert) < Google gecko < Open AI text embedding 3 large
- all-miniLM (Sbert) being a small model is faster, it is also default embedding for vector database like chroma
https://huggingface.co/spaces/mteb/leaderboard
Embeddings are a fundamental concept in deep learning that enable us to capture rich context in binary format. Roy Keyes: “Embeddings are learned transformations to make data more useful.”
Three key aspects of embeddings: they are learned, they transform data, and they make data more useful. They are learned usually via some variation of a neural network and transforms raw data into vectors, making the data more useful by capturing meaning and context in a machine readable and indexable format.
- Tokenization
The process of transforming text into embeddings begins with tokenization, which is the process of breaking down text into smaller parts, or “tokens.” These tokens can be as small as individual characters or as large as entire sentences, However, in most cases they represent individual words or sub-words. A pioneering method that has evolved this process is Word2Vec, which was developed at google in 2013. It operates by grouping the vectors of similar words together in a vector space. This is achieved by creating dense vector representations of word features, such as the context of individual words. Given enough data and a variety of contexts, Word2Vec can make accurate predictions about a word’s meaning based on its past appearances. For instance, it can infer that “man” is to “boy” what “woman” is to “girl” based on the contexts in which these words appear.
Word2Vec uses a neural network to train words against other words that neighbor them in the input corpus. It does this in one of two ways: either using the context to predict a target word, a method known as Continuous Bag of Words (CBOW), or using a word to predict a target context, which is called Skip-Gram. When the feature vector assigned to a word cannot accurately predict that word’s context, the components of the vector are adjusted, refining the model’s understanding of semantic relationships. This iterative process of adjustment and refinement is at the heart of Word2Vec’s power and effectiveness.
Word2Vec has some limitations. It cannot handle polysemy, which is when a single word or phrase has multiple meanings (e.g. river “bank”, money “bank”), which prevents it from differentiating between multiple meanings of a word based on context. Additionally it must store a vector for every unique word in the vocabulary which causes the size of the model to grow with the size of the corpus vocabulary, becoming a limiting factor for larger data sets. It also struggles with handling out-of-vocabulary words, or words that were not present in the training corpus which can lead to inaccurate representations. Lastly, Word2Vec does not account for morphological variations of words. For instance, it treats “run,” “runs,” and “running” as entirely separate words with no inherent relationship, which can lead to a loss of semantic understanding.
Sub-word tokenization allows the model to have a reasonable vocabulary size while being able to learn meaningful context-independent representations. For instance BERT and GPT-2 limit the vocabulary size to 30,000 to 50,000 tokens by using WordPiece and Byte Pair Encodings respectively. In addition, sub-word tokenization enables the model to process words it has never seen before, by decomposing them into known sub-words. For instance, if a model trained with sub-word tokenization encounters the word “unseenword”, it could potentially break it down into known sub-words like “un”, “seen”, and “word”. Now there are a number of different methodologies that use the sub-word approach to tokenize words.
Transformer Models
Words are tokenized to address how text is transformed into their final embeddings, while preserving the semantic meaning of the text on a larger scale. Vector databases generally use encoder-only transformer models; an example of this would be BERT (Bidirectional Encoder Representations from Transformers). We only need to encode the text so that it can be compared with the other embedded bodies of text in the database. Once we know which embeddings are most similar we can use their unique ids to look up the original raw text. These models leverage the power of self-attention mechanisms and positional encodings to understand the context and semantics of words in a sentence. Let’s break down this process into its key steps:
- Tokenization: The number of tokens fed to the model at one time can range anywhere from the size of a sentence, a paragraph, all the way up to a small document.
- Embedding Lookup: Once the text is tokenized, each token is mapped to an initial embedding. These embeddings are not random but are pre-trained representations learned during the pere-training phase of the Transformer model. They serve as the starting point for understanding the semantics of each token.
- Positional Encoding: Transformers, by design, lack an inherent understanding of the order of tokens. To overcome this, positional encodings are added to the initial embeddings. These encodings provide information about the position of each token within the sequence, enabling the model to understand the order of words, while freeing us from the constraint of sequential processing of a text that limited processing in pre-transformer NLP models like RNNs.
- Self-Attention Mechanism: The next step involves the application of the self-attention mechanism. This mechanism allows each token to ‘look’ at other tokens in the sequence and weigh their influence based on their relevance. It enables the model to determine which tokens contribute significantly to the meaning of each individual token.
- Aggregation: Following the self-attention step, the outputs for each token are aggregated, typically by summing them up. This aggregation results in a new set of embeddings for each token. These embeddings capture both the individual meanings of the tokens and their context within the sequence. The aggregation step combines the context-aware embeddings from the self-attention mechanism into a single vector.
- Feed-Forward Neural Network: The final step in the process involves passing these aggregated embeddings through a feed-forward neural network. This network processes the embeddings to produce the final set of embeddings and is shared across all positions. The feed-forward neural network further transforms these embeddings, enabling the model to learn more abstract representations, and it helps to generalize the model to unseen data.
The resulting embeddings are rich in semantic and contextual information, making them incredibly useful for a wide range of natural language processing tasks. In the context of vector databases, these embeddings serve as the high-dimensional vectors that are stored and queried to retrieve semantically similar results.
A larger vocabulary equates to more embeddings, which in turn increases the model’s size and the computational resources needed for training and inference. This is why models like BERT and GPT use various sub-word tokenization methods in order to train on a huge corpus of text, while keeping the number of tokens relatively low.
The issue of out-of-vocabulary words can also impact the quality of the embeddings. Sub-word tokenization allows the model to construct representations for unseen words from the sub-word units it has encountered. Certain tokenization methods may be more suitable for specific tasks or languages. This can result in more accurate embeddings and improved performance on tasks such as search.
Tokenization method can significantly affect the size and effectiveness of a transformer model’s embeddings. It’s a crucial consideration when designing and training these models, and it should be guided by the specific requirements of the task and the characteristics of the language of the text. Many vector databases make this determination automatically, but one may achieve superior performance in vector search by experimenting with different tokenization methods and transformer models.
Encoder only transformer models are fundamental to transforming the tokenized words into indexable and comparable context of a larger corpus of text. Through a series of steps — tokenization, embedding lookup, positional encoding, self-attention mechanism, aggregation, and a feed-forward neural network — these models create embeddings that capture both the semantic meaning of each token and the context in which it appears in the sequence.By choosing the right tokenization method we can create a nuanced understanding of text that captures both the meaning of individual words and the relationships between them.
Appendix: Specific sub-word tokenization methods
- Byte Pair Encoding (BPE)
- How it works: BPE starts with a vocabulary of individual characters and iteratively merges the most frequent pair of symbols to produce a new symbol. This process continues until a predefined number of merges have been made.
- Advantages: BPE can handle out-of-vocabulary words and morphological variations. It’s flexible and can adapt to the specifics of the language it’s trained on.
- Disadvantages: BPE can sometimes produce strange splits of words, especially for languages with complex morphology. It also requires a two-step process of first learning the BPE merges and then training the model.
- Used in: GPT-2, RoBERTa.
- Example: Given the word “lowers” and the most frequent pair is (“o”, “w”), BPE will merge them into a new symbol “ow”. The word “lowers” will be tokenized into “l”, “ow”, “e”, “r”, “s”.
2. Byte-Level Encoding
- How it works: Byte-level encoding uses a vocabulary of all possible byte values (256 unique bytes). It can handle any string of bytes, making it particularly useful for multilingual models or models that need to handle non-text inputs.
- Advantages: Byte-level encoding can handle any kind of input and doesn’t require any special handling for out-of-vocabulary words. It’s also very memory-efficient.
- Disadvantages: Byte-level encoding can sometimes produce very long sequences for languages that use multi-byte characters (like Chinese or Japanese).
- Used in: GPT-3.
- Example: The word “hello” will be tokenized into the corresponding byte values of each character: 104, 101, 108, 108, 111.
3. Word Piece
- How it works: Word Piece is similar to BPE but it prefers to keep whole words intact. It starts with a base vocabulary of individual characters and then learns a fixed number of merges, similar to BPE.
- Advantages: Word Piece can handle out-of-vocabulary words and it’s less likely to split words in strange ways compared to BPE.
- Disadvantages: Word Piece can still produce unexpected splits and it requires a two-step process of first learning the merges and then training the model.
- Used in: BERT, DistilBERT.
- Example: Given the word “lowers” and the most frequent pair is (“low”, “ers”), Word Piece will merge them into a new symbol “lowers”.
4. Unigram
- How it works: Unigram tokenization is a subword regularization method that learns a subword vocabulary by minimizing the loss of the likelihood of the training data.
- Advantages: Unigram can handle out-of-vocabulary words and it’s more flexible than BPE or Word Piece because it allows for multiple possible segmentations of a word.
- Disadvantages: Unigram can sometimes produce unexpected splits and it requires a two-step process of first learning the merges and then training the model.
- Used in: SentencePiece.
- Example: Given the word “I love machine learning” [“I”, “ “, “a”, “d”, “o”, “r”, “e”, “ “, “machine”, “ “, “learning”]
5. SentencePiece
- How it works: SentencePiece is a language-independent subword tokenizer and detokenizer. It treats the input as a raw input string, so you don’t need to pre-tokenize the text. SentencePiece implements both BPE and unigram language model with the extension of direct training from raw sentences.
- Advantages: SentencePiece allows for the flexibility of BPE and unigram language model while also being able to handle multiple languages in one model. It doesn’t require any pre-tokenization.
- Disadvantages: SentencePiece can sometimes produce unexpected splits, and the choice between BPE and unigram may not be clear for every application.
- Used in: Multilingual BERT, T2T (Tensor2Tensor).
- Example: Given the sentence “This is a test.”, SentencePiece might tokenize it into [“▁This”, “▁is”, “▁a”, “▁test”, “.”], where “▁” represents a space.



